LSTM(Long Short-Term Memory)은 자연어 처리, 시계열 및 기타 시퀀스 모델링 작업에 사용되는 RNN 신경망의 한 종류이다.
여기서는 단방향(unidirection) LSTM모델을 Tensorflow2로 어떻게 구현할 수 있는지 그 방법에 대해서 알아보고자 한다. 실제로 코드를 작성하기 전에 먼저 LSTM의 구조와 내부 작동에 대해서 이해하는 것이 순서이겠지만, 이에 대해서는 다음에 포스팅하기로 하고 일단 LSTM 모델을 Tensorflow2 코드로 구현하는 것에 집중하도록 하겠다.
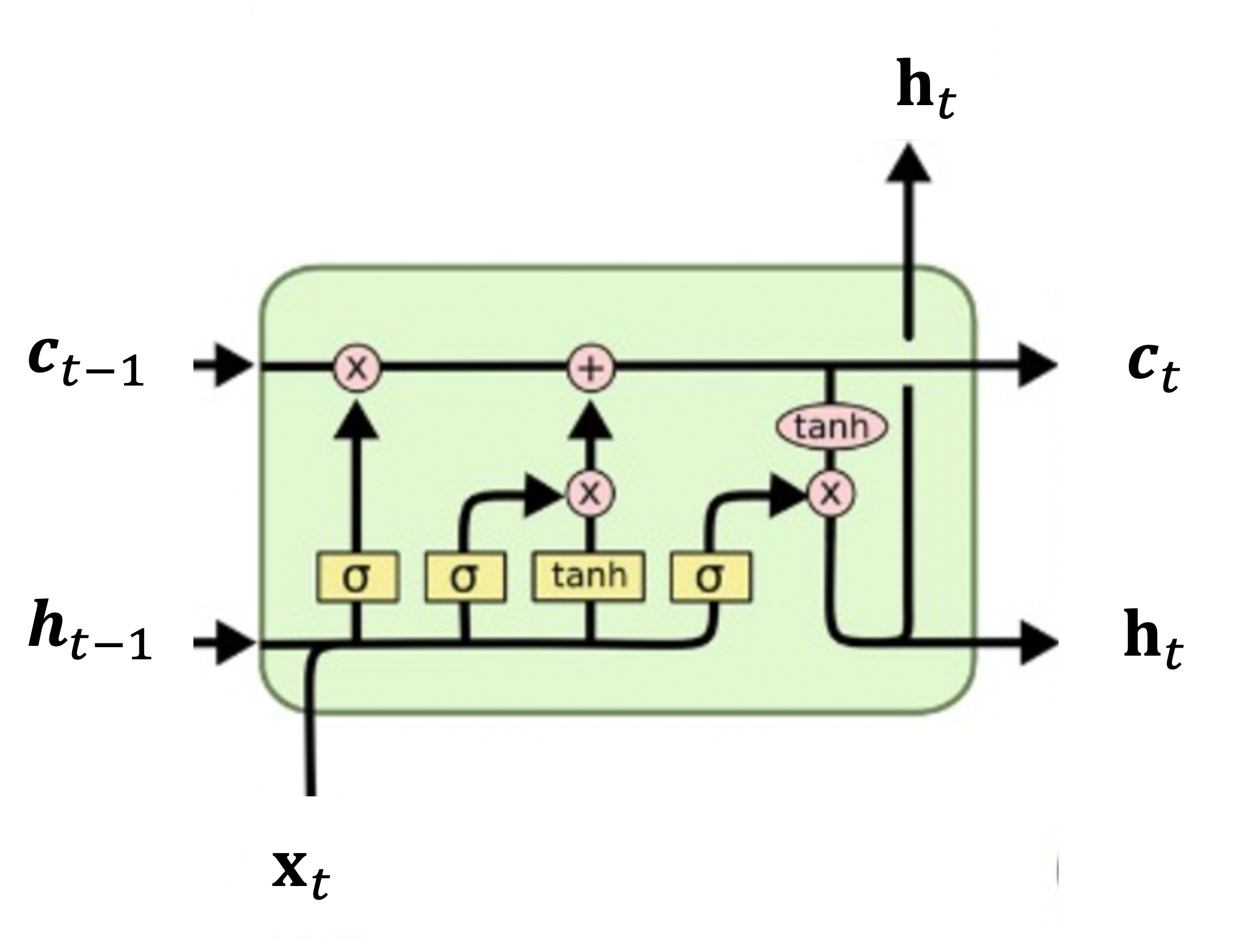
LSTM의 모든 기능은 그림에서 녹색 메모로 표시된 메모리셀(memory cell)이라는 곳에서 수행된다. 메모리셀은 3개의 입력과 2개의 출력이 있다. 입력으로는 은닉 상태(hidden state) \(\mathbf{h}_{t-1}\), 셀 상태(cell state) \(\mathbf{c}_{t-1}\), 그리고 외부 입력 \(\mathbf{x}_t\) 가 있고, 출력으로는 은닉 상태 \(\mathbf{h}_t\) 와 셀 상태 \(\mathbf{c}_t\) 가 있다. \(t\) 는 현재의 시간 스텝 또는 시퀀스를 나타낸다. 은닉 상태와 셀 상태는 이전 셀에서 다음 셀로 차례로 전파되어서 이전 셀의 출력이 현재 셀의 입력으로 사용되며, 현재 셀의 출력이 다음 셀의 입력으로 사용된다.
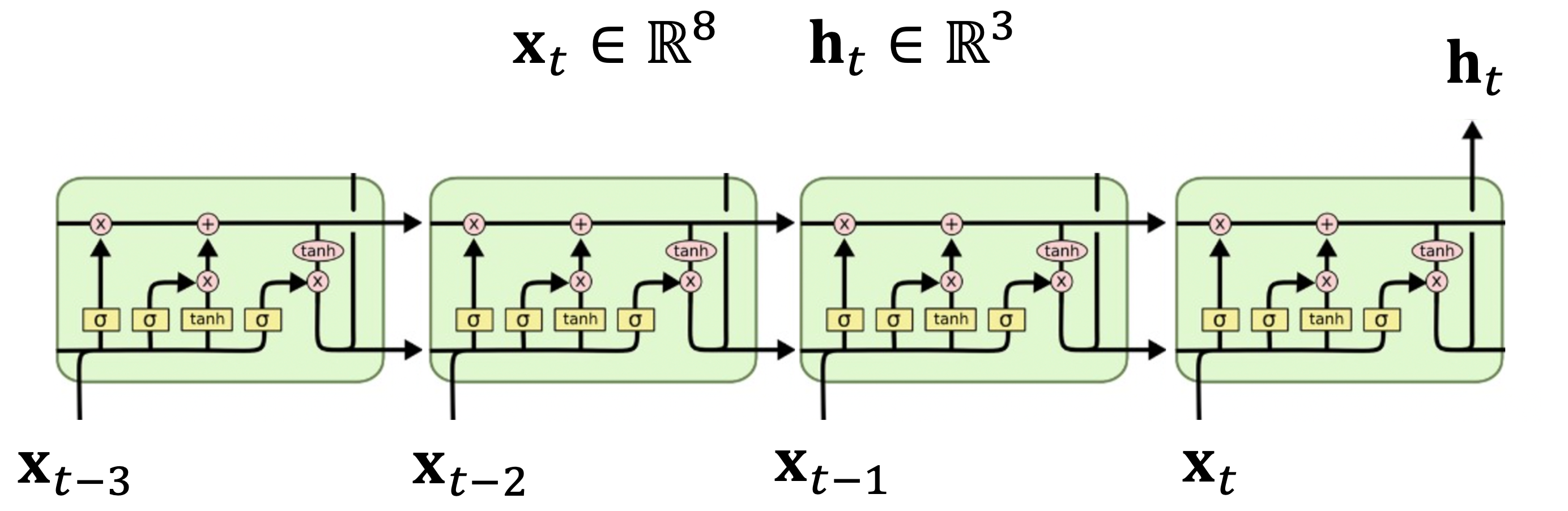
Tensorflow에서는 tf.keras.layers.LSTM 클래스를 통해서 LSTM을 표현하는데 먼저 단순한 단방향 모델부터 구현하면서 이 클래스의 구조를 살펴보도록 하자. 다음 그림은 시퀀스 길이가 4 (\(t-3, t-2, t-1, t\)), 은닉 상태변수의 차원이 \(\mathbf{h}_t \in \mathbb{R}^3\), 입력 변수의 차원이 \(\mathbf{x}_t \in \mathbb{R}^8\) 인 LSTM 모델을 나타낸 것이다.
이 모델을 tf.keras.layers.LSTM 을 이용하여 구현하면 다음과 같다.
model_1 = tf.keras.models.Sequential()
model_1.add(tf.keras.layers.LSTM(units=3, input_shape=(4,8))) # (seq_len, input dimension)
model_1.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 3) 144
=================================================================
Total params: 144
Trainable params: 144
Non-trainable params: 0
또는 다음과 같이 구현할 수도 있다.
input = tf.keras.layers.Input(shape=(4,8)) # (seq length, input dimension)
lstm = tf.keras.layers.LSTM(units=3)(input)
model_2 = tf.keras.models.Model(inputs=input, outputs=lstm)
model_2.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 4, 8)] 0
lstm_1 (LSTM) (None, 3) 144
=================================================================
Total params: 144
Trainable params: 144
Non-trainable params: 0
units 속성은 은닉 상태의 차원을 나타낸다. input은 (시퀀스 길이, 입력 변수의 차원) 순으로 표시해 주면 된다. 예를 들어서 배치(batch) 사이즈 32, 시퀀스 길이 10, 입력 차원 8인 임의의 입력에 대해서 은닉 상태의 차원이 4인 LSTM 모델은 다음과 같이 구현할 수 있다.
# batch 32, hidden 4, seq_len 10, input_dim 8
inputs = tf.random.normal([32, 10, 8])
lstm = tf.keras.layers.LSTM(units=4)
output = lstm(inputs)
print(output.shape)
그러면 output의 차원은 (32,4) 로 나온다.
다음 코드는 many-to-one 의 전형적인 예제로서 입력이 1,2,3 일 때 4가 나오고, 2,3,4 일 때 5가, 3,4,5 일 때 6이, 4,5,6 일 때 7이 나오도록 학습시키는 LSTM 모델이다. 구조는 아래 그림과 같다.
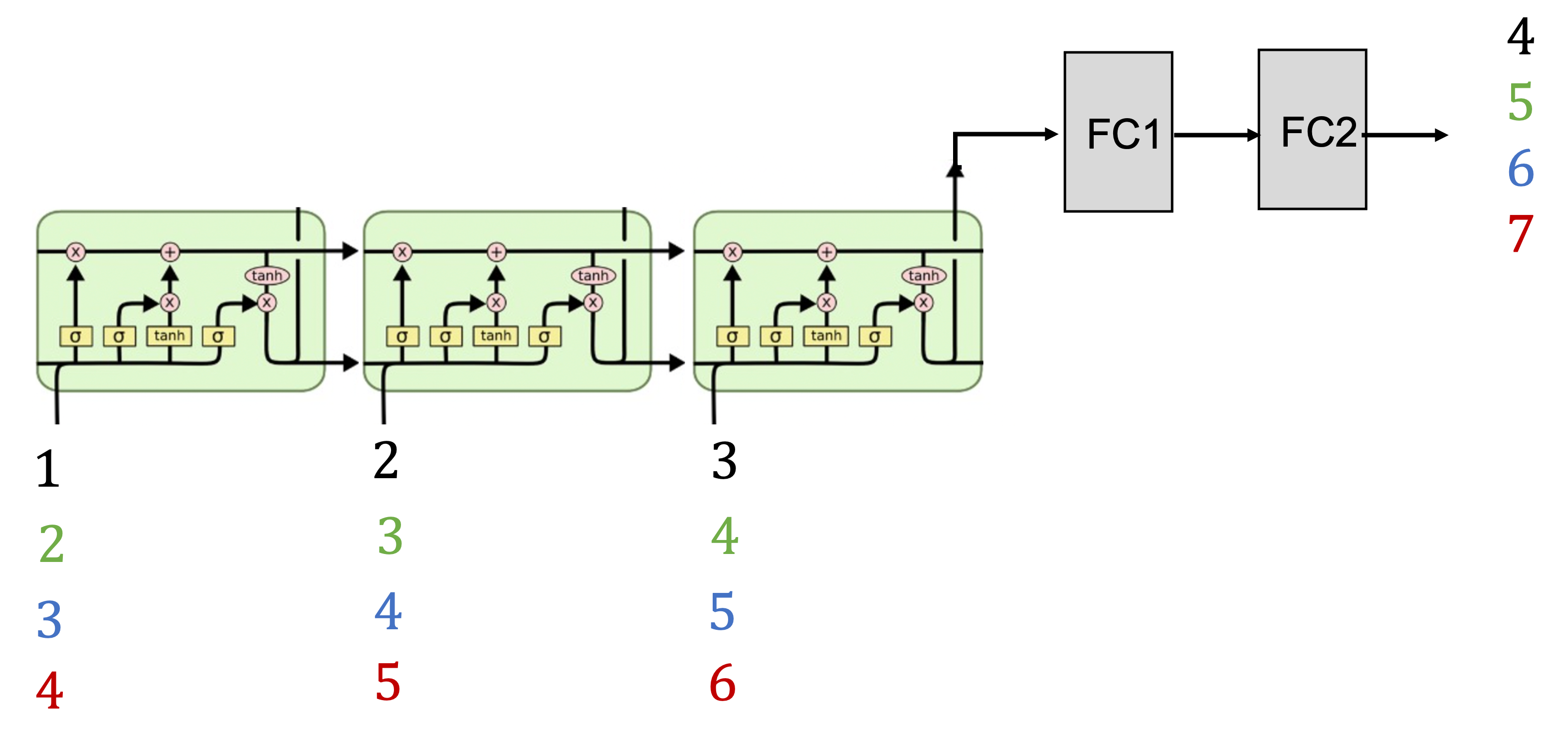
시퀀스 길이가 3, 입력 차원이 1, 은닉 상태의 차원이 10인 LSTM 의 출력에 사이즈가 각각 10과 1인 완전연결(FC) 레이어가 2개 연결되어 있다. 먼저 입력과 출력 데이터는 다음과 같다.
# input-output data : 123->4, 234->5, 345->6, 456->7
x = array([ [1,2,3], [2,3,4], [3,4,5], [4,5,6]])
y = array([4,5,6,7])
입력 데이터는 (배치 사이즈, 시퀀스 길이, 입력 차원) 순으로 정렬해야 한다.
x = x.reshape((4,3,1)) #(data size(batch), seq_length, input dim)
모델은 다음과 같이 구현한다.
model = Sequential()
model.add(LSTM(units=10, activation='relu', input_shape=(3,1))) # (seq_len, input length)
model.add(Dense(10))
model.add(Dense(1))
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 10) 480
dense (Dense) (None, 10) 110
dense_1 (Dense) (None, 1) 11
=================================================================
Total params: 601
Trainable params: 601
Non-trainable params: 0
여기서 LSTM의 디폴트 활성함수인 'tanh' 대신에 'relu' 를 사용하기 위해서 속성 activation='relu' 를 사용했다. Adam 옵티마이저와 MSE 오차 함수를 사용하고 100번의 이폭(epoch)으로 학습한다.
model.compile(optimizer='adam', loss='mse')
model.fit(x, y, epochs=100, batch_size=1)
모델을 학습 시킨 후 입력으로 6,7,8을 주었을 때 9가 나오는지 확인해 본다.
x_input = array([7,8,9])
x_input = x_input.reshape((1,3,1))
yhat = model.predict(x_input)
print(yhat)
결과는 9.25가 나왔다.
'AI 딥러닝 > Sequence' 카테고리의 다른 글
| [seq2seq] 어텐션이 포함된 seq2seq 모델 (0) | 2023.08.23 |
|---|---|
| [seq2seq] 간단한 seq2seq 모델 구현 (0) | 2023.08.17 |
| [LSTM] LSTM-AE를 이용한 시퀀스 데이터 이상 탐지 (0) | 2023.05.31 |
| [LSTM] 주가 예측 (0) | 2023.05.19 |
| [LSTM] TF2에서 단방향 LSTM 모델 구현 - 2 (0) | 2022.07.23 |




댓글