Sequence-to-sequence 또는 seq2seq 모델은 입력 시퀀스(sequence)를 출력 시퀀스로 변환하는 신경망 모델이다. seq2seq 모델은 한 도메인의 시퀀스를 다른 도메인의 시퀀스로 변환해야 하는 기계 번역, 대화 시스템, 질문 응답, 텍스트 요약, 이미지 또는 비디오 캡셔닝, 음성인식, 시계열 예측과 같은 분야에서 큰 성공을 거두었다.
기본적으로 seq2seq 모델은 인코더(encoder)와 디코더(decoder), 그리고 두 블록을 연결하는 컨텍스트 벡터(context vector)로 구성되어 있다. 인코더는 입력 시퀀스에 대한 정보를 고정된 길이를 갖는 컨텍스트 벡터로 압축한다. 컨텍스트 벡터는 디코더가 정확한 예측을 수행하는 데 도움이 되는 방식으로 구축된다. 디코더는 컨텍스트 벡터를 이용하여 출력 시퀀스로 변환한다.

다른 신경망 모델과 마찬가지로 seq2seq 모델도 학습을 위해서는 방대한 양의 학습 데이터가 필요하다. 학습 데이터는 입력 시퀀스와 이에 대응하는 출력 시퀀스의 쌍으로 구성된다. seq2seq 모델에는 다양한 종류가 있다. 예를 들면 인코더와 디코더 모델로 LSTM 을 사용하기도 하고 GRU(gated recurrent unit)를 사용하기도 한다. 이 때 이 모델을 단방향 또는 양방향(bidirection)으로 구현하기도 하고, 단층 레이어 또는 다층 레이어를 사용하기도 한다. 또한 어텐션 메카니즘(attention mechanism)과 같은 추가 기능을 사용하기도 한다.
하지만 여기서는 가장 기본적인 seq2seq 모델 구조를 이용하여 시퀀스 변환 예제를 Tensorflow2 로 구현해 보고자 한다. 참고한 사이트는
2. https://keras.io/examples/nlp/lstm_seq2seq/
3. https://keras.io/examples/nlp/bidirectional_lstm_imdb/
이다. 구현된 Tensorflow2 코드는 모두 유사하지만 2번과 3번 사이트는 조금 복잡한 예제를 다루었다. 1번 사이트는 간단한 예제를 다루었기 때문에 seq2seq 모델과 코드 구현에 대해 설명하는데 적절한 것으로 생각된다.
구현하고자 하는 예제는 다음과 같이 0~9 범위를 갖는 seq_len 길이(그림에서는 길이가 5)의 입력 숫자열을 반대 순서로 정렬된 숫자열로 변환하여 출력시키는 것이다. 본 예제에서는 인코더와 디코더 모델로 각각 단방향, 단층 LSTM을 사용한다.
seq2seq 모델의 구조는 5가지로 구분할 수 있다.
먼저 인코더 임베딩(embedding) 레이어가 있다. 인코더 임베딩 레이어는 입력 시퀀스의 각 성분(기계번역에서는 입력 문장의 단어에 해당)을 임베딩 벡터로 변환한다. 여기서는 길이가 10인 원핫(one-hot) 벡터로 변환한다. 예를 들면
두번째는 인코더 LSTM 레이어다. 임베딩 벡터의 길이가 10, 입력 시퀀스의 길이가 seq_len 이므로, 외부 입력은
인코더 LSTM 모델을 Tensorflow2로 구현하면 다음과 같다.
class Encoder(Model):
def __init__(self, hidden_state_dim=16):
super(Encoder, self).__init__()
self.lstm = LSTM(units=hidden_state_dim, return_state=True)
def call(self, enc_input):
# out=(batch, hidden_dim), h_st=(batch, hidden_dim), c_st=(batch, hidden_dim)
out, h_st, c_st = self.lstm(enc_input)
encoder_states = [h_st, c_st]
return encoder_states
Model: "encoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) multiple 1728
=================================================================
Total params: 1728 (6.75 KB)
Trainable params: 1728 (6.75 KB)
Non-trainable params: 0 (0.00 Byte)
return_state = True 를 한 경우에는 마지막 시퀀스에서의 출력(은닉상태), 은닉상태
세번째로 디코더 임베딩 레이어는 출력 시퀀스의 각 성분(기계번역에서는 입력 문장의 단어에 해당)을 임베딩 벡터로 변환한다. 여기서는 인코더 임베딩과 마찬가지로 길이가 10인 원핫(one-hot) 벡터로 변환한다.
네번째는 디코더 LSTM 레이어다. 인코더와 마찬가지로 임베딩 벡터의 길이가 10, 입력 시퀀스의 길이가 seq_len 이므로, 외부 입력은
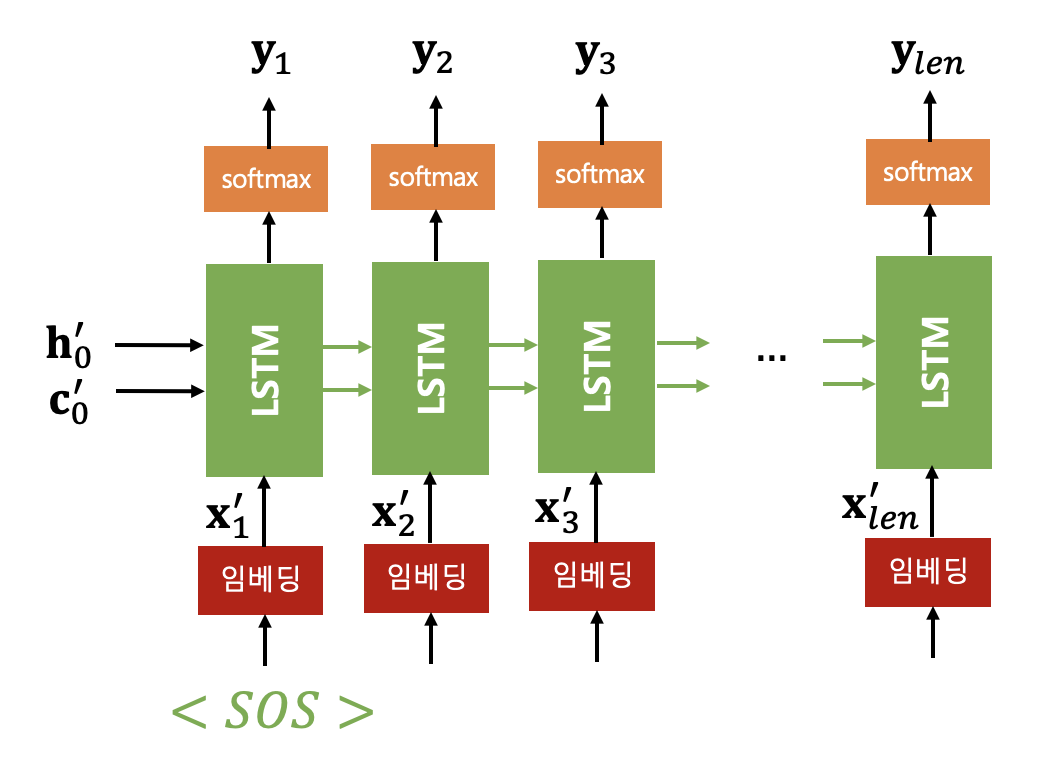
디코더의 초기 상태
임의의 시퀀스 스텝
예를 들어
디코더의 첫번째 외부 입력은 특수기호 'SOS' 이다. 출력 시퀀스의 시작을 나타내는데 사용되는 것으로 start of sequence를 의미한다. 여기서는 'SOS'를 변환한 원핫(one-hot) 벡터
디코더 LSTM 모델을 Tensorflow2로 구현하면 다음과 같다.
class Decoder(Model):
def __init__(self, n_tokens, hidden_state_dim=16):
super(Decoder, self).__init__()
self.lstm = LSTM(units=hidden_state_dim, return_sequences=True, return_state=True)
self.fc = Dense(n_tokens, activation='softmax')
def call(self, dec_input, encoder_states):
# out=(batch, seq_len, hidden_dim), h_st=(batch, hidden_dim), c_st=(batch, hidden_dim)
out, h_st, c_st = self.lstm(dec_input, initial_state=encoder_states)
dec_out = self.fc(out) # (batch, seq_len, n_tokens)
return dec_out, h_st, c_st
Model: "decoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) multiple 1728
dense (Dense) multiple 170
=================================================================
Total params: 1898 (7.41 KB)
Trainable params: 1898 (7.41 KB)
Non-trainable params: 0 (0.00 Byte)
return_sequences와 return_state를 모두 True로 설정하면 각 시퀀스별 은닉상태와 마지막 은닉 상태, 마지막 셀상태 값이 출력된다. 인코더와 디코더를 연결하여 seq2seq 모델을 Tensorflow2로 구현하면 다음과 같다.
class Seq2seq(Model):
def __init__(self, n_tokens, hidden_state_dim=16):
super(Seq2seq, self).__init__()
self.encoder = Encoder(hidden_state_dim)
self.decoder = Decoder(n_tokens, hidden_state_dim)
def call(self, enc_dec_input):
enc_input = enc_dec_input[0]
dec_input = enc_dec_input[1]
enc_context = self.encoder(enc_input)
dec_out, _, _ = self.decoder(dec_input, enc_context)
return dec_out
다섯번째는 포스트 프로세싱 레이어이다. 이 단계에서는 출력된 임베딩 값을 원래 도메인 값으로 복원한다. 예를 들면
seq2seq 에서 디코더는 인코더와는 달리 학습 단계와 실행 단계에서 다르게 작동한다. 학습 단계에서는 시퀀스 스텝
구체적으로 설명하면 다음과 같다. 입력 시퀀스가 다음과 같다고 하자.
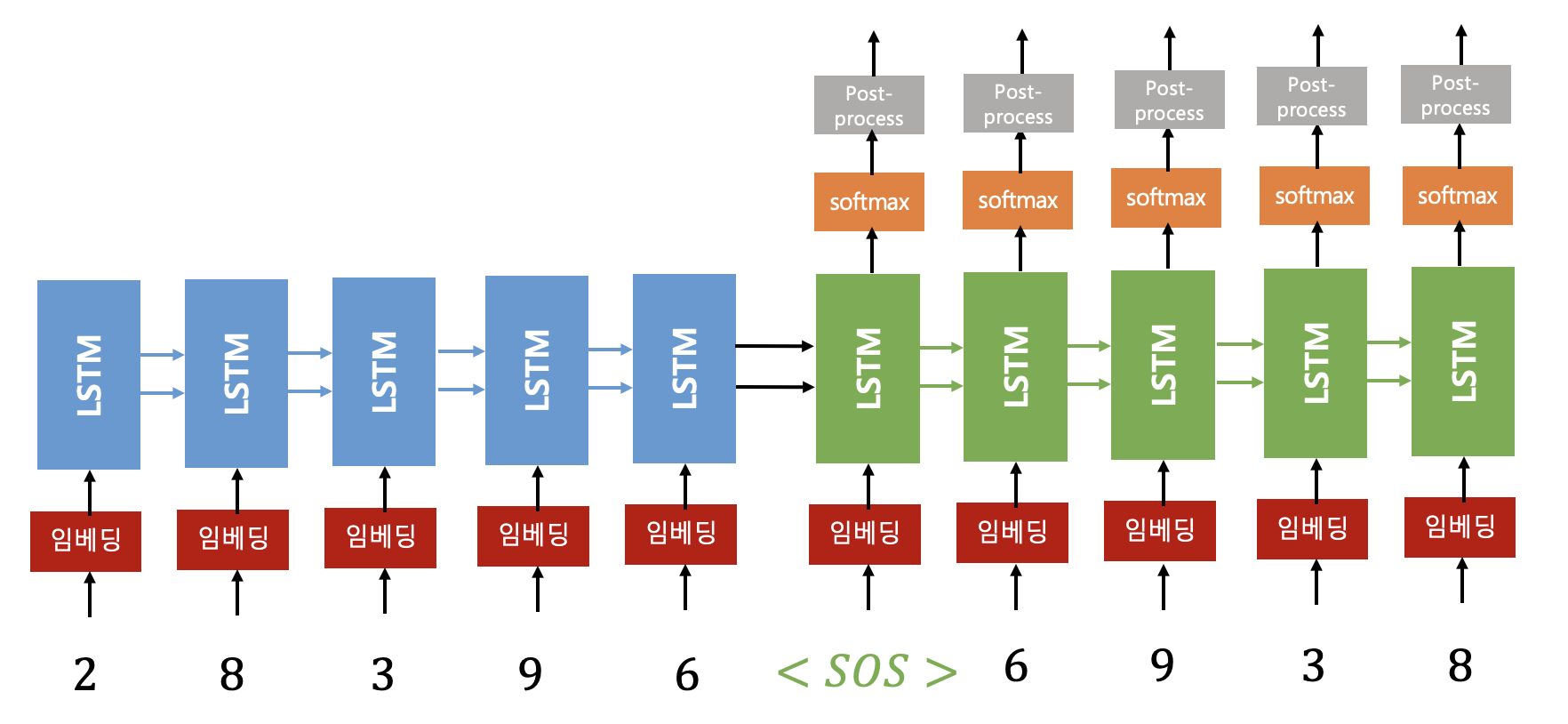
다음은 학습 부분을 Tensorflow2로 구현한 것이다.
def train(self, epochs):
X_encoder, X_decoder, y = \
create_dataset(self.TRAIN_SIZE, self.SEQ_LEN, self.N_TOKENS, verbose=False)
history = self.s2s.fit(
[X_encoder, X_decoder],
y,
batch_size=self.BATCH_SIZE,
epochs=epochs,
validation_split=0.2,
verbose=2
)
# save
self.s2s.save_weights("./save_weights/s2s.h5")
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r-', label='val_loss')
plt.xlabel('epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k-', label='val_accuracy')
plt.xlabel('epoch')
plt.legend()
plt.show()
학습이 끝나고 실행단계는 다음과 같이 작동한다. 시퀀스
디코더에서는 첫번째 시퀀스 스텝
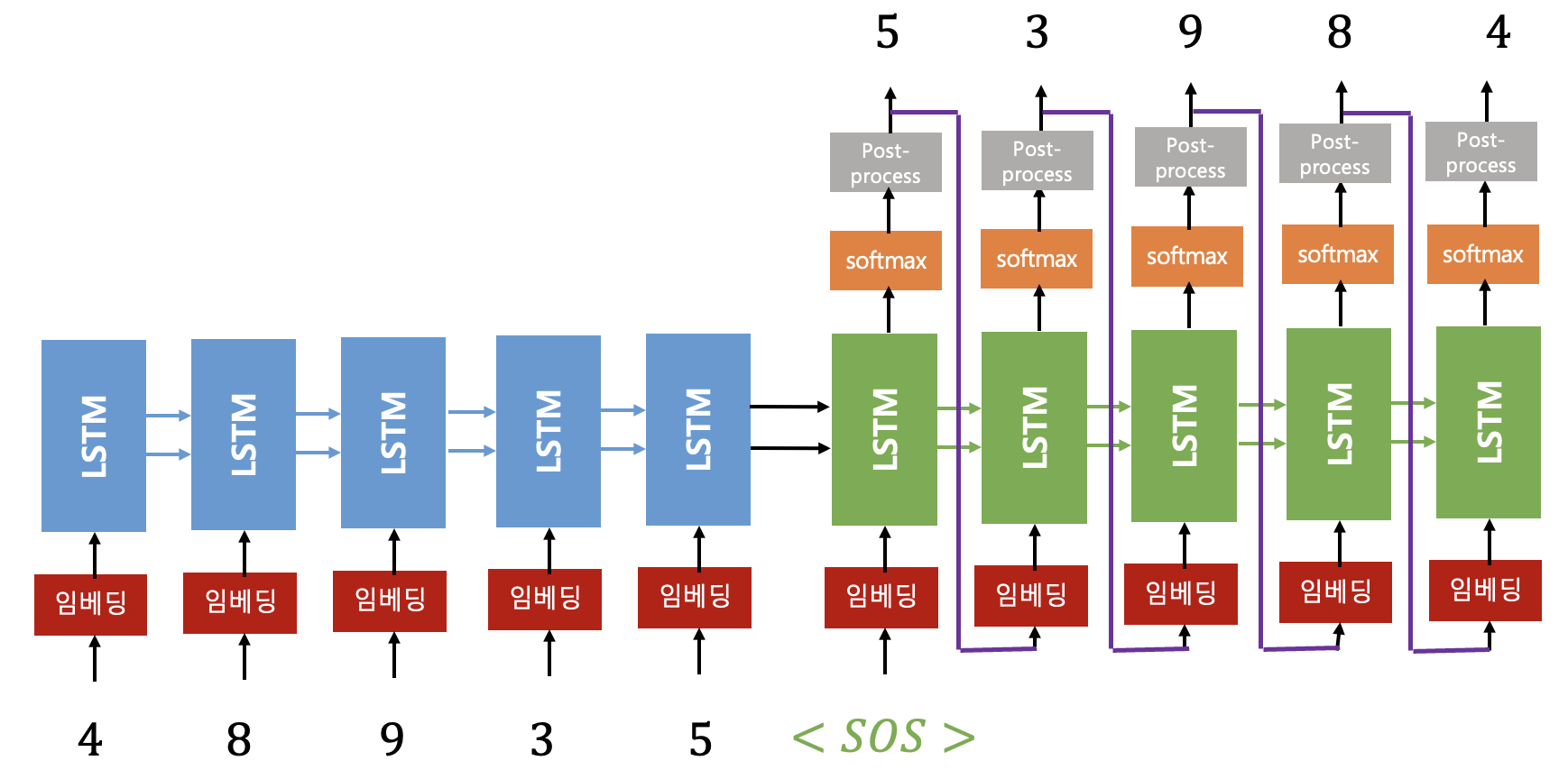
다음은 실행 부분을 Tensorflow2로 구현한 것이다.
def decode_seq(self, input_seq, true_seq):
# input_seq=(seq_len, n_tokens)
# true_seq=(seq_len, n_tokens)
if os.path.exists('./save_weights/s2s.h5'):
self.s2s.load_weights("./save_weights/s2s.h5")
else:
return 0
print('Input \t\t\t\t Exact \t\t\t Predicted \t\tT/F')
correct = 0
n_seq = input_seq.shape[0]
for seq_idx in range(0, n_seq):
# take one sequence at a time
decoded_seq = self.single_decode_seq(
tf.reshape(input_seq[seq_idx], (1, self.SEQ_LEN, self.N_TOKENS)))
if (one_hot_decode(true_seq[seq_idx]) == decoded_seq):
correct += 1
print(one_hot_decode(input_seq[seq_idx]), '\t',
one_hot_decode(true_seq[seq_idx]), '\t', decoded_seq,
'\t', one_hot_decode(true_seq[seq_idx]) == decoded_seq)
print('Accuracy: ', correct / n_seq)
def single_decode_seq(self, single_input_seq):
# single_input_seq=(n_seq, seq_len, n_tokens)
# encode the input sequence as context vector
context_value = self.s2s.encoder(single_input_seq)
# generate empty dec_input sequence of length 1.
dec_input_seq = np.zeros((1, 1, self.N_TOKENS)) # (1, seq_len, input_dim)
# make <sos>
dec_input_seq[0, 0, 0] = 1
# looping for a batch of sequences
stop_condition = False
decoded_seq = list()
while not stop_condition:
# decode the input
dec_out, h_st, c_st = self.s2s.decoder(dec_input_seq, context_value)
# predict the decoder output using argmax
sampled_digit = np.argmax(dec_out[0, -1, :])
# add the predicted token/output to output sequence
decoded_seq.append(sampled_digit)
# stop condition: hit max length
if (len(decoded_seq) == self.SEQ_LEN):
stop_condition = True
# update the decoder input sequence for the next LSTM cell
dec_input_seq = np.zeros((1, 1, self.N_TOKENS))
dec_input_seq[0, 0, sampled_digit] = 1.
# update context value
context_value = [h_st, c_st]
return decoded_seq
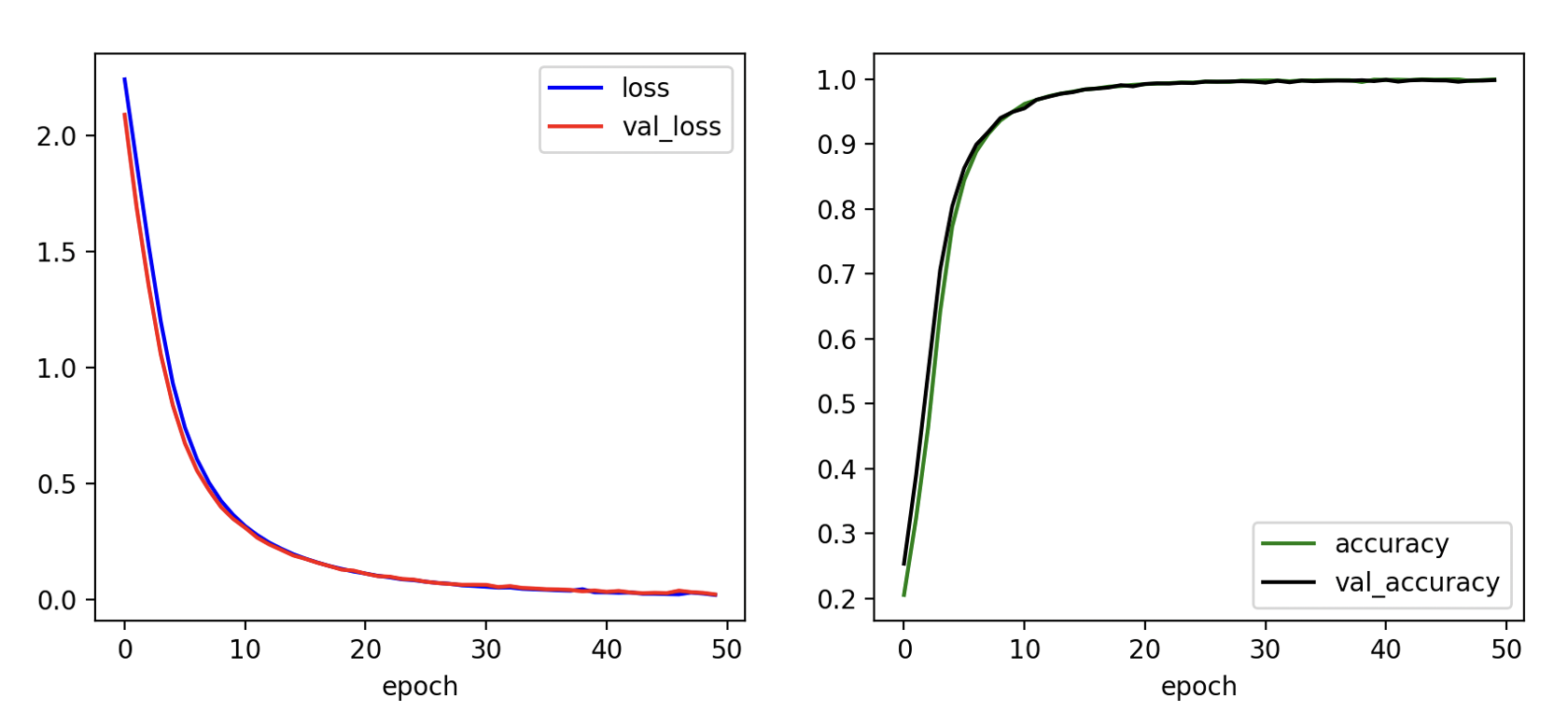
데이터셋 5000개로 이폭 50, 시퀀스 길이 5로 학습한 결과는 다음과 같다.
Epoch 47/50
125/125 - 2s - loss: 0.0243 - accuracy: 0.9984 - val_loss: 0.0351 - val_accuracy: 0.9944 - 2s/epoch - 15ms/step
Epoch 48/50
125/125 - 2s - loss: 0.0184 - accuracy: 0.9995 - val_loss: 0.0206 - val_accuracy: 0.9988 - 2s/epoch - 15ms/step
Epoch 49/50
125/125 - 2s - loss: 0.0176 - accuracy: 0.9995 - val_loss: 0.0312 - val_accuracy: 0.9952 - 2s/epoch - 15ms/step
Epoch 50/50
125/125 - 2s - loss: 0.0196 - accuracy: 0.9989 - val_loss: 0.0307 - val_accuracy: 0.9958 - 2s/epoch - 15ms/step
임의로 생성된 10개의 시퀀스 데이터에 대해서 테스트한 결과는 다음과 같다.
Input Exact Predicted T/F
[3, 5, 0, 0, 6] [6, 0, 0, 5, 3] [6, 0, 0, 5, 3] True
[1, 5, 0, 8, 0] [0, 8, 0, 5, 1] [0, 8, 0, 5, 1] True
[0, 6, 6, 1, 1] [1, 1, 6, 6, 0] [1, 1, 6, 6, 0] True
[1, 6, 6, 2, 8] [8, 2, 6, 6, 1] [8, 2, 6, 6, 1] True
[2, 1, 2, 6, 0] [0, 6, 2, 1, 2] [0, 6, 2, 1, 2] True
[2, 4, 8, 3, 7] [7, 3, 8, 4, 2] [7, 3, 8, 4, 2] True
[4, 7, 2, 3, 7] [7, 3, 2, 7, 4] [7, 3, 2, 7, 4] True
[5, 1, 8, 3, 6] [6, 3, 8, 1, 5] [6, 3, 8, 1, 5] True
[4, 5, 9, 9, 7] [7, 9, 9, 5, 4] [7, 9, 9, 5, 4] True
[6, 3, 7, 7, 0] [0, 7, 7, 3, 6] [0, 7, 7, 3, 6] True
Accuracy: 1.0
성공률 100%가 나왔다. 이번에는 재미삼아 시퀀스 길이 4인 데이터로 테스트해봤다. 결과는 다음과 같다.
Input Exact Predicted T/F
[3, 1, 9, 8] [8, 9, 1, 3] [8, 9, 1, 3] True
[2, 8, 8, 9] [9, 8, 8, 2] [9, 8, 8, 2] True
[9, 1, 5, 9] [9, 5, 1, 9] [9, 5, 1, 9] True
[7, 9, 9, 5] [5, 9, 9, 7] [5, 9, 9, 8] False
[8, 6, 1, 3] [3, 1, 6, 8] [3, 1, 6, 8] True
[2, 1, 8, 4] [4, 8, 1, 2] [4, 8, 1, 2] True
[6, 0, 0, 9] [9, 0, 0, 6] [9, 0, 6, 0] False
[9, 0, 7, 3] [3, 7, 0, 9] [3, 7, 9, 8] False
[5, 4, 3, 0] [0, 3, 4, 5] [0, 3, 4, 5] True
[0, 3, 5, 7] [7, 5, 3, 0] [7, 5, 3, 8] False
Accuracy: 0.6
성공률 60%가 나왔다. 이번에는 시퀀스 길이 6인 데이터로도 테스트했다.
Input Exact Predicted T/F
[3, 7, 0, 8, 4, 3] [3, 4, 8, 0, 7, 3] [3, 4, 8, 0, 3, 0] False
[5, 3, 5, 5, 7, 1] [1, 7, 5, 5, 3, 5] [1, 7, 5, 5, 3, 6] False
[5, 8, 5, 0, 8, 4] [4, 8, 0, 5, 8, 5] [4, 8, 0, 5, 8, 6] False
[5, 6, 9, 4, 0, 2] [2, 0, 4, 9, 6, 5] [2, 0, 4, 0, 6, 1] False
[1, 4, 7, 1, 0, 2] [2, 0, 1, 7, 4, 1] [2, 0, 1, 7, 5, 2] False
[5, 2, 0, 7, 8, 8] [8, 8, 7, 0, 2, 5] [8, 8, 7, 0, 0, 6] False
[5, 0, 7, 0, 2, 1] [1, 2, 0, 7, 0, 5] [1, 2, 0, 7, 0, 5] True
[9, 1, 3, 5, 5, 9] [9, 5, 5, 3, 1, 9] [9, 5, 5, 3, 1, 6] False
[6, 5, 8, 3, 9, 9] [9, 9, 3, 8, 5, 6] [9, 9, 3, 8, 5, 6] True
[9, 3, 7, 0, 6, 3] [3, 6, 0, 7, 3, 9] [3, 6, 0, 0, 7, 6] False
Accuracy: 0.2
성공률 20%가 나왔다. 시퀀스 길이 5인 데이터로 학습했기 때문에 아무래도 다른 길이를 갖는 시퀀스 데이터에 대해서는 테스트 결과가 좋지 못하다.
다음은 Tensorflow2 전체 코드다.
s2s_model.py
# Seq2Seq model
# coded by st.watermelon
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import LSTM, Dense
class Encoder(Model):
def __init__(self, hidden_state_dim=16):
super(Encoder, self).__init__()
self.lstm = LSTM(units=hidden_state_dim, return_state=True)
def call(self, enc_input):
# out=(batch, hidden_dim), h_st=(batch, hidden_dim), c_st=(batch, hidden_dim)
out, h_st, c_st = self.lstm(enc_input)
encoder_states = [h_st, c_st]
return encoder_states
class Decoder(Model):
def __init__(self, n_tokens, hidden_state_dim=16):
super(Decoder, self).__init__()
self.lstm = LSTM(units=hidden_state_dim, return_sequences=True, return_state=True)
self.fc = Dense(n_tokens, activation='softmax')
def call(self, dec_input, encoder_states):
# out=(batch, seq_len, hidden_dim), h_st=(batch, hidden_dim), c_st=(batch, hidden_dim)
out, h_st, c_st = self.lstm(dec_input, initial_state=encoder_states)
dec_out = self.fc(out) # (batch, seq_len, n_tokens)
return dec_out, h_st, c_st
class Seq2seq(Model):
def __init__(self, n_tokens, hidden_state_dim=16):
super(Seq2seq, self).__init__()
self.encoder = Encoder(hidden_state_dim)
self.decoder = Decoder(n_tokens, hidden_state_dim)
def call(self, enc_dec_input):
enc_input = enc_dec_input[0]
dec_input = enc_dec_input[1]
enc_context = self.encoder(enc_input)
dec_out, _, _ = self.decoder(dec_input, enc_context)
return dec_out
s2s_train.py
# Seq2Seq train
# coded by st.watermelon
from s2s_model import Seq2seq
from gen_data import *
import os
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, LSTM, Dense
""" setup Seq2Seq agent """
class S2Sagent(Model):
def __init__(self, seq_len):
super(S2Sagent, self).__init__()
# hyperparameters
self.TRAIN_SIZE = 5000
self.SEQ_LEN = seq_len
self.N_TOKENS = 10
self.BATCH_SIZE = 32
self.HIDDEN_STATE_DIM = 16
self.LEARNING_RATE = 1e-3
# create seq2seq
self.s2s = Seq2seq(self.N_TOKENS, self.HIDDEN_STATE_DIM)
# compile
self.s2s.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adam(self.LEARNING_RATE),
metrics=['accuracy']
)
encoder_input = Input((self.SEQ_LEN, self.N_TOKENS))
decoder_input = Input((self.SEQ_LEN, self.N_TOKENS))
self.s2s([encoder_input, decoder_input])
self.s2s.encoder.summary()
self.s2s.decoder.summary()
self.s2s.summary()
def train(self, epochs):
X_encoder, X_decoder, y = \
create_dataset(self.TRAIN_SIZE, self.SEQ_LEN, self.N_TOKENS, verbose=False)
history = self.s2s.fit(
[X_encoder, X_decoder],
y,
batch_size=self.BATCH_SIZE,
epochs=epochs,
validation_split=0.2,
verbose=2
)
# save
self.s2s.save_weights("./save_weights/s2s.h5")
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r-', label='val_loss')
plt.xlabel('epoch')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], 'g-', label='accuracy')
plt.plot(history.history['val_accuracy'], 'k-', label='val_accuracy')
plt.xlabel('epoch')
plt.legend()
plt.show()
def decode_seq(self, input_seq, true_seq):
# input_seq=(seq_len, n_tokens)
# true_seq=(seq_len, n_tokens)
if os.path.exists('./save_weights/s2s.h5'):
self.s2s.load_weights("./save_weights/s2s.h5")
else:
return 0
print('Input \t\t\t\t Exact \t\t\t Predicted \t\tT/F')
correct = 0
n_seq = input_seq.shape[0]
for seq_idx in range(0, n_seq):
# take one sequence at a time
decoded_seq = self.single_decode_seq(
tf.reshape(input_seq[seq_idx], (1, self.SEQ_LEN, self.N_TOKENS)))
if (one_hot_decode(true_seq[seq_idx]) == decoded_seq):
correct += 1
print(one_hot_decode(input_seq[seq_idx]), '\t',
one_hot_decode(true_seq[seq_idx]), '\t', decoded_seq,
'\t', one_hot_decode(true_seq[seq_idx]) == decoded_seq)
print('Accuracy: ', correct / n_seq)
def single_decode_seq(self, single_input_seq):
# single_input_seq=(n_seq, seq_len, n_tokens)
# encode the input sequence as context vector
context_value = self.s2s.encoder(single_input_seq)
# generate empty dec_input sequence of length 1.
dec_input_seq = np.zeros((1, 1, self.N_TOKENS)) # (1, seq_len, input_dim)
# make <sos>
dec_input_seq[0, 0, 0] = 1
# looping for a batch of sequences
stop_condition = False
decoded_seq = list()
while not stop_condition:
# decode the input
dec_out, h_st, c_st = self.s2s.decoder(dec_input_seq, context_value)
# predict the decoder output using argmax
sampled_digit = np.argmax(dec_out[0, -1, :])
# add the predicted token/output to output sequence
decoded_seq.append(sampled_digit)
# stop condition: hit max length
if (len(decoded_seq) == self.SEQ_LEN):
stop_condition = True
# update the decoder input sequence for the next LSTM cell
dec_input_seq = np.zeros((1, 1, self.N_TOKENS))
dec_input_seq[0, 0, sampled_digit] = 1.
# update context value
context_value = [h_st, c_st]
return decoded_seq
if __name__ == "__main__":
seq_len = 5
agent = S2Sagent(seq_len)
agent.train(50)
s2s_load_play.py
# Seq2Seq inference
# coded by st.watermelon
from s2s_train import S2Sagent
from gen_data import create_dataset
def main():
seq_len = 5
agent = S2Sagent(seq_len)
input_seq, _, true_seq = create_dataset(10, seq_len, 10, verbose=False)
agent.decode_seq(input_seq, true_seq)
if __name__ == "__main__":
main()
gen_data.py
# generating data for seq2seq
# coded by st.watermelon
from random import randint
import numpy as np
import tensorflow as tf
# generate a sequence of random integers
def generate_sequence(seq_len, n_tokens):
return [randint(0, n_tokens - 1) for _ in range(seq_len)]
# one hot encode sequence
def one_hot_encode(sequence, n_tokens):
encoding = list()
for value in sequence:
vector = [0 for _ in range(n_tokens)]
vector[value] = 1
encoding.append(vector)
return np.array(encoding)
# decode a one hot encoded string
def one_hot_decode(encoded_seq):
return [np.argmax(vector) for vector in encoded_seq]
# prepare data for the LSTM
def get_reversed_triple(seq_len, n_tokens, verbose=False):
# generate random sequence
sequence_in = generate_sequence(seq_len, n_tokens)
sequence_out = sequence_in[::-1]
sequence_out_with_start = sequence_out.copy()
sequence_out_with_start.insert(0, 0)
sequence_out_with_start.pop()
# one hot encode
X_incoder = one_hot_encode(sequence_in, n_tokens)
X_decoder = one_hot_encode(sequence_out_with_start, n_tokens)
y = one_hot_encode(sequence_out, n_tokens)
# reshape as 3D
X_incoder = X_incoder.reshape((1, X_incoder.shape[0], X_incoder.shape[1]))
X_decoder = X_decoder.reshape((1, X_decoder.shape[0], X_decoder.shape[1]))
y = y.reshape((1, y.shape[0], y.shape[1]))
if (verbose):
print('\nSample X_incoder, X_decoder and y')
print('\nIn raw format:')
print('X_incoder=%s' % (one_hot_decode(X_incoder[0])))
print('X_decoder=%s' % (one_hot_decode(X_decoder[0])))
print('y=%s' % (one_hot_decode(y[0])))
print('\nIn one_hot_encoded format:')
print('X_incoder=%s' % (X_incoder[0]))
print('X_decoder=%s' % (X_decoder[0]))
print('y=%s' % (y[0]))
return [np.array(X_incoder), np.array(X_decoder), np.array(y)]
def create_dataset(train_size, seq_len, n_tokens, verbose=False):
X_encoder = list()
X_decoder = list()
y = list()
for _ in range(train_size):
triple = get_reversed_triple(seq_len, n_tokens)
X_encoder.append(triple[0])
X_decoder.append(triple[1])
y.append(triple[2])
X_encoder = np.array(X_encoder).squeeze()
X_decoder = np.array(X_decoder).squeeze()
y = np.array(y).squeeze()
if (verbose):
print('\nGenerated sequence datasets as follows')
print('X_encoder.shape: ', X_encoder.shape)
print('X_decoder.shape: ', X_decoder.shape)
print('y.shape: ', y.shape)
print('Sample sequences in raw format:')
print('X_encoder: \n', one_hot_decode(X_encoder[0]))
print('X_decoder: \n', one_hot_decode(X_decoder[0]))
print('y: \n', one_hot_decode(y[0]))
print('Sample sequences in one-hot encoded format:')
print('X_encoder: \n', X_encoder[0])
print('X_decoder: \n', X_decoder[0])
print('y: \n', y[0])
# Convert the datasets to float32
X_encoder = tf.cast(X_encoder, tf.float32)
X_decoder = tf.cast(X_decoder, tf.float32)
y = tf.cast(y, tf.float32)
return X_encoder, X_decoder, y
if __name__ == "__main__":
seq_len = 5
n_enc_tokens = 10
# generate datasets
train_size = 3
encoder_input_data, decoder_input_data, decoder_true_data = \
create_dataset(train_size, seq_len, n_enc_tokens, verbose=True)
print(encoder_input_data.shape)
'AI 딥러닝 > Sequence' 카테고리의 다른 글
| [PtrNet] Pointer Net 구조 (0) | 2023.09.12 |
|---|---|
| [seq2seq] 어텐션이 포함된 seq2seq 모델 (0) | 2023.08.23 |
| [LSTM] LSTM-AE를 이용한 시퀀스 데이터 이상 탐지 (0) | 2023.05.31 |
| [LSTM] 주가 예측 (0) | 2023.05.19 |
| [LSTM] TF2에서 단방향 LSTM 모델 구현 - 2 (0) | 2022.07.23 |




댓글