OpenAI Gym에서 제공하는 Pendulum-v0 환경을 대상으로 A2C 알고리즘을 Tensorflow2 코드로 구현하였다.
학습결과는 다음과 같다.
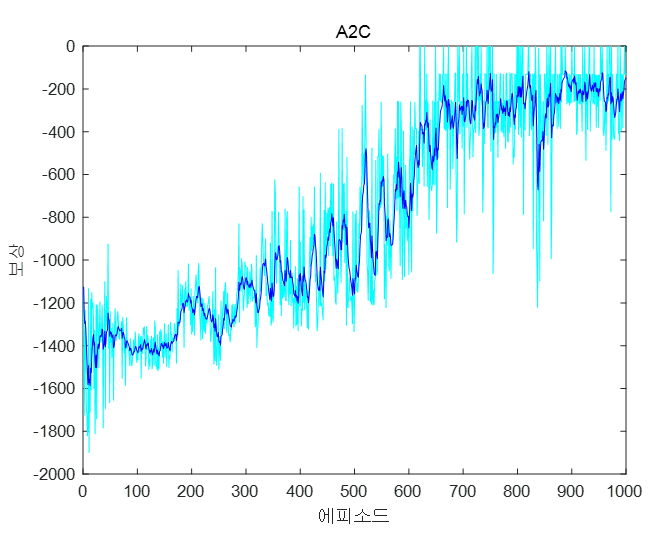
A2C 코드는 액터-크리틱 신경망을 구현하고 학습시키기 위한 a2c_learn.py, 이를 실행시키기 위한 a2c_main.py, 그리고 학습을 마친 신경망 파라미터를 읽어와 에이전트를 구동하기 위한 a2c_load_play.py로 구성되어 있다.
전체 코드 구조는 다음과 같다.

다음은 Tensorflow2 코드다.
a2c_learn.py
# A2C learn (tf2 subclaasing API version)
# coded by St.Watermelon
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Lambda
from tensorflow.keras.optimizers import Adam
import numpy as np
import matplotlib.pyplot as plt
# actor network
class Actor(Model):
def __init__(self, action_dim, action_bound):
super(Actor, self).__init__()
self.action_bound = action_bound
self.h1 = Dense(64, activation='relu')
self.h2 = Dense(32, activation='relu')
self.h3 = Dense(16, activation='relu')
self.mu = Dense(action_dim, activation='tanh')
self.std = Dense(action_dim, activation='softplus')
def call(self, state):
x = self.h1(state)
x = self.h2(x)
x = self.h3(x)
mu = self.mu(x)
std = self.std(x)
# Scale output to [-action_bound, action_bound]
mu = Lambda(lambda x: x*self.action_bound)(mu)
return [mu, std]
# critic network
class Critic(Model):
"""
Critic Network for A2C: V function approximator
"""
def __init__(self):
super(Critic, self).__init__()
self.h1 = Dense(64, activation='relu')
self.h2 = Dense(32, activation='relu')
self.h3 = Dense(16, activation='relu')
self.v = Dense(1, activation='linear')
def call(self, state):
x = self.h1(state)
x = self.h2(x)
x = self.h3(x)
v = self.v(x)
return v
# a2c agent for training
class A2Cagent(object):
def __init__(self, env):
# hyperparameters
self.GAMMA = 0.95
self.BATCH_SIZE = 32
self.ACTOR_LEARNING_RATE = 0.0001
self.CRITIC_LEARNING_RATE = 0.001
self.env = env
# get state dimension
self.state_dim = env.observation_space.shape[0]
# get action dimension
self.action_dim = env.action_space.shape[0]
# get action bound
self.action_bound = env.action_space.high[0]
self.std_bound = [1e-2, 1.0] # std bound
# create actor and critic networks
self.actor = Actor(self.action_dim, self.action_bound)
self.critic = Critic()
self.actor.build(input_shape=(None, self.state_dim))
self.critic.build(input_shape=(None, self.state_dim))
self.actor.summary()
self.critic.summary()
# optimizer
self.actor_opt = Adam(self.ACTOR_LEARNING_RATE)
self.critic_opt = Adam(self.CRITIC_LEARNING_RATE)
# save the results
self.save_epi_reward = []
## log policy pdf
def log_pdf(self, mu, std, action):
std = tf.clip_by_value(std, self.std_bound[0], self.std_bound[1])
var = std ** 2
log_policy_pdf = -0.5 * (action - mu) ** 2 / var - 0.5 * tf.math.log(var * 2 * np.pi)
return tf.reduce_sum(log_policy_pdf, 1, keepdims=True)
## actor policy
def get_action(self, state):
mu_a, std_a = self.actor(state)
mu_a = mu_a.numpy()[0]
std_a = std_a.numpy()[0]
std_a = np.clip(std_a, self.std_bound[0], self.std_bound[1])
action = np.random.normal(mu_a, std_a, size=self.action_dim)
return action
## train the actor network
def actor_learn(self, states, actions, advantages):
with tf.GradientTape() as tape:
# policy pdf
mu_a, std_a = self.actor(states, training=True)
log_policy_pdf = self.log_pdf(mu_a, std_a, actions)
# loss function and its gradients
loss_policy = log_policy_pdf * advantages
loss = tf.reduce_sum(-loss_policy)
grads = tape.gradient(loss, self.actor.trainable_variables)
self.actor_opt.apply_gradients(zip(grads, self.actor.trainable_variables))
## single gradient update on a single batch data
def critic_learn(self, states, td_targets):
with tf.GradientTape() as tape:
td_hat = self.critic(states, training=True)
loss = tf.reduce_mean(tf.square(td_targets-td_hat))
grads = tape.gradient(loss, self.critic.trainable_variables)
self.critic_opt.apply_gradients(zip(grads, self.critic.trainable_variables))
## computing targets: y_k = r_k + gamma*V(x_k+1)
def td_target(self, rewards, next_v_values, dones):
y_i = np.zeros(next_v_values.shape)
for i in range(next_v_values.shape[0]): # number of batch
if dones[i]:
y_i[i] = rewards[i]
else:
y_i[i] = rewards[i] + self.GAMMA * next_v_values[i]
return y_i
## load actor wieghts
def load_weights(self, path):
self.actor.load_weights(path + 'pendulum_actor.h5')
self.critic.load_weights(path + 'pendulum_critic.h5')
## convert (list of np.array) to np.array
def unpack_batch(self, batch):
unpack = batch[0]
for idx in range(len(batch)-1):
unpack = np.append(unpack, batch[idx+1], axis=0)
return unpack
## train the agent
def train(self, max_episode_num):
for ep in range(int(max_episode_num)):
# initialize batch
batch_state, batch_action, batch_reward, batch_next_state, batch_done = [], [], [], [], []
# reset episode
time, episode_reward, done = 0, 0, False
# reset the environment and observe the first state
state = self.env.reset() # shape of state from gym (3,)
while not done:
# visualize the environment
#self.env.render()
# reshape of state (state_dim,) -> (1,state_dim)
action = self.get_action(tf.convert_to_tensor([state], dtype=tf.float32))
# clip continuous action to be within action_bound
action = np.clip(action, -self.action_bound, self.action_bound)
# observe reward, new_state, shape of output of gym (state_dim,)
next_state, reward, done, _ = self.env.step(action)
# change shape (state_dim,) -> (1, state_dim), same to action, next_state
state = np.reshape(state, [1, self.state_dim])
action = np.reshape(action, [1, self.action_dim])
reward = np.reshape(reward, [1, 1])
next_state = np.reshape(next_state, [1, self.state_dim])
done = np.reshape(done, [1, 1])
# compute advantage and TD target
train_reward = (reward + 8) / 8 # <-- normalization
# append to the batch
batch_state.append(state)
batch_action.append(action)
batch_reward.append(train_reward)
batch_next_state.append(next_state)
batch_done.append(done)
# continue until batch becomes full
if len(batch_state) < self.BATCH_SIZE:
# update current state
state = next_state[0]
episode_reward += reward[0]
time += 1
continue
# if batch is full, start to train networks on batch
# extract batched states, actions, ...
states = self.unpack_batch(batch_state)
actions = self.unpack_batch(batch_action)
train_rewards = self.unpack_batch(batch_reward)
next_states = self.unpack_batch(batch_next_state)
dones = self.unpack_batch(batch_done)
# clear the batch
batch_state, batch_action, batch_reward, batch_next_state, batch_done = [], [], [], [], []
# compute next v_value with previous V estimate
next_v_values = self.critic(tf.convert_to_tensor(next_states, dtype=tf.float32))
td_targets = self.td_target(train_rewards, next_v_values.numpy(), dones)
# train critic
self.critic_learn(tf.convert_to_tensor(states, dtype=tf.float32),
tf.convert_to_tensor(td_targets, dtype=tf.float32))
# compute advantages
v_values = self.critic(tf.convert_to_tensor(states, dtype=tf.float32))
next_v_values = self.critic(tf.convert_to_tensor(next_states, dtype=tf.float32))
advantages = train_rewards + self.GAMMA * next_v_values - v_values
# train actor
self.actor_learn(tf.convert_to_tensor(states, dtype=tf.float32),
tf.convert_to_tensor(actions, dtype=tf.float32),
tf.convert_to_tensor(advantages, dtype=tf.float32))
# update current state
state = next_state[0]
episode_reward += reward[0]
time += 1
## display rewards every episode
print('Episode: ', ep+1, 'Time: ', time, 'Reward: ', episode_reward)
self.save_epi_reward.append(episode_reward)
## save weights every episode
if ep % 10 == 0:
self.actor.save_weights("./save_weights/pendulum_actor.h5")
self.critic.save_weights("./save_weights/pendulum_critic.h5")
np.savetxt('./save_weights/pendulum_epi_reward.txt', self.save_epi_reward)
print(self.save_epi_reward)
## save them to file if done
def plot_result(self):
plt.plot(self.save_epi_reward)
plt.show()
a2c_main.py
# A2C main
# coded by St.Watermelon
from a2c_learn import A2Cagent
import gym
def main():
max_episode_num = 1000
env_name = 'Pendulum-v0'
env = gym.make(env_name)
agent = A2Cagent(env)
agent.train(max_episode_num)
agent.plot_result()
if __name__=="__main__":
main()
a2c_load_play.py
# A2C main (tf2 version)
# coded by St.Watermelon
import gym
import tensorflow as tf
from a2c_learn import A2Cagent
def main():
env_name = 'Pendulum-v0'
env = gym.make(env_name)
agent = A2Cagent(env)
agent.load_weights('./save_weights/')
time = 0
state = env.reset()
while True:
env.render()
action = agent.actor(tf.convert_to_tensor([state], dtype=tf.float32))[0][0]
state, reward, done, _ = env.step(action)
time += 1
print('Time: ', time, 'Reward: ', reward)
if done:
break
env.close()
if __name__=="__main__":
main()
'AI 딥러닝 > RL' 카테고리의 다른 글
| 강화학습에서의 이산공간과 연속공간 문제 (0) | 2021.04.26 |
|---|---|
| 가치함수 (Value Function) (0) | 2021.04.21 |
| A2C 알고리즘-2: 액터 신경망 (0) | 2021.04.20 |
| A2C 알고리즘-1: 크리틱 신경망 (0) | 2021.04.20 |
| 정책 그래디언트 기반 강화학습의 원리 (0) | 2021.04.13 |




댓글