이산시간(discrete-time)이란 시간 변수가 특정 지점에서만 값을 갖는 것을 의미한다. 반면에 연속시간(continuous-time)이란 시간 변수가 연속적인 값을 갖는 것을 의미한다. 가령 특정 시간 구간 \([t_0, t_f ]\)에서 가질 수 있는 시간 지점이 \(t=t_0, t_1, ..., t_f\)로서 유한개라면 이산시간이고, \(t_0 \le t \le t_f\)로서 무한개라면 연속시간이다. 이산시간에서는 시간 전개를 시간스텝(time-step)으로 표현한다.
이산공간(discrete-space)이란 시간 이외의 어떤 변수가 특정 지점에서만 값을 갖는 것을 의미한다. 반면에 연속공간(continuous-space)이란 시간 이외의 어떤 변수가 연속적인 값을 갖는 것을 의미한다. 가령 어떤 물체에 가할 수 있는 힘(force)이 \(F \in \{1, 2, 4, 7 \} \ N\) 에 있는 값 중에서 한 값만 가질 수 있다면 힘을 이산공간으로 표현한 것이고, \(1 \le F \le 7 \ N\) 이라면 연속공간에서 표현한 것이다.
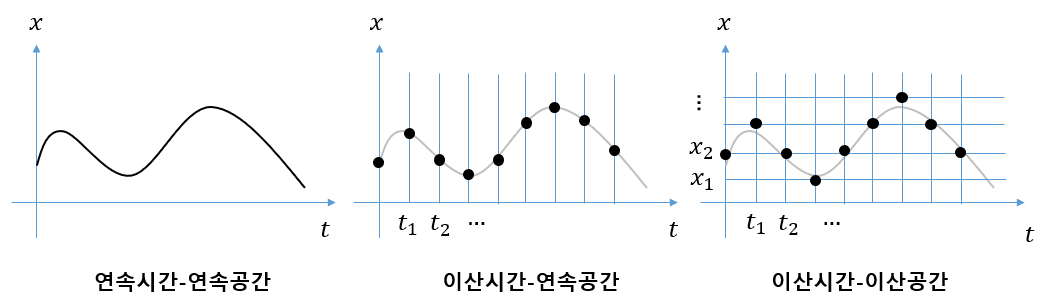
어떤 시스템의 수학적 운동 모델을 만들 때, 목적이나 문제에 따라서 시간을 이산시간이나 연속시간 중에서 선택하고, 모델의 상태변수나 행동변수를 이산공간이나 연속공간 중에서 선택하여 모델링할 수 있다. 일반적인 강화학습 문제는 이산시간+이산공간 또는 이산시간+연속공간의 조합으로 표현된다.
디랙델타(Direc delta) 함수 \(\delta (x)\)를 이용하면 다음과 같이 이산공간에서의 확률 \(P\{X=x_i\}\)를 연속공간에서의 확률밀도함수 \(p_X (x)\)의 형태로 표시할 수 있다.
\[ p_X (x)= \sum_{i=1}^N P\{X=x_i\} \delta (x-x_i ) \]
여기서 \(x_i\)는 이산공간에서 랜덤변수 \(X\)가 가질 수 있는 \(N\)개의 모든 원소다. 이를 이용하면 강화학습 문제에서 연속공간에서 주어지는 확률밀도함수를 이산공간에서는 확률로 해석할 수 있다.

예를 들어보자. 연속공간상에서 상태가치 함수와 행동가치 함수의 관계는 다음과 같았다.
\[ \begin{align} V^\pi (\mathbf{x}_t ) &= \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ Q^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right] \\ \\ &= \int_{\mathbf{u}_t} Q^\pi (\mathbf{x}_t, \mathbf{u}_t ) \pi (\mathbf{u}_t | \mathbf{x}_t ) d \mathbf{u}_t \end{align} \]
여기서 \(\pi( \mathbf{u}_t | \mathbf{x}_t )\)는 조건부 확률밀도함수다.
이제 행동이 이산공간 상에 있다고 하자. 즉 행동은 \(\mathcal{A}\) 라는 집합의 원소 중에서 한 값만 가질 수 있다고 하자. 연속공간 상의 행동 표기와 구별하기 위해서 여기서는 전통적인 강화학습 표기대로 행동을 \(\mathbf{a}_t= \mathbf{a} \in \mathcal{A}\)라고 표기하겠다.
그러면, 상태가치 함수는 다음과 같이 된다.
\[ \begin{align} V^\pi (\mathbf{x}_t ) &= \int_{\mathbf{u}_t} Q^\pi (\mathbf{x}_t, \mathbf{u}_t ) \pi (\mathbf{u}_t | \mathbf{x}_t ) d \mathbf{u}_t \\ \\ &= \int_{\mathbf{u}_t} Q^\pi (\mathbf{x}_t, \mathbf{u}_t ) \sum_{\mathbf{a}_t \in \mathcal{A}} P\{ \mathbf{u}_t = \mathbf{a}_t | \mathbf{x}_t \} \delta ( \mathbf{u}_t - \mathbf{a}_t ) d \mathbf{u}_t \\ \\ &= \sum_{\mathbf{a}_t \in \mathcal{A}} P\{ \mathbf{u}_t = \mathbf{a}_t | \mathbf{x}_t \} Q^\pi (\mathbf{x}_t, \mathbf{a}_t ) \\ \\ &= \sum_{\mathbf{a}_t \in \mathcal{A}} \pi (\mathbf{a}_t | \mathbf{x}_t ) Q^\pi (\mathbf{x}_t, \mathbf{a}_t ) \\ \\ &= \mathbb{E}_{ \mathbf{a}_t \sim \pi (\mathbf{a}_t | \mathbf{x}_t) } \left[ Q^\pi (\mathbf{x}_t, \mathbf{a}_t ) \right] \end{align} \]
여기서 표기의 일관성을 위해서 정책의 조건부 확률 \( \pi (\mathbf{a}_t | \mathbf{x}_t) = P\{ \mathbf{u}_t = \mathbf{a}_t | \mathbf{x}_t \} \)를 확률밀도함수와 동일하게 표기했다. 행동이 이산공간 값인지 연속공간 값인지에 따라서 \(\pi (\mathbf{a}_t | \mathbf{x}_t) \)가 확률인지 확률밀도함수인지 명백하므로 혼동은 없을 것이다.
연속공간의 상태가치 함수식과 비교해 보면 행동에 관련된 적분을 시그마(합)으로 바꾸면 된다는 것을 알 수 있다.
만약 상태변수도 이산공간 상에 있다면 즉, \(\mathbf{s}_t=\mathbf{s} \in \mathcal{S}\)이라면, 위 식은 다음과 같이 된다.
\[ \begin{align} V^\pi (\mathbf{x}_t ) &= \sum_{\mathbf{a}_t \in \mathcal{A}} \pi (\mathbf{a}_t | \mathbf{s}_t ) Q^\pi (\mathbf{s}_t, \mathbf{a}_t ) \\ \\ &= \mathbb{E}_{ \mathbf{a}_t \sim \pi (\mathbf{a}_t | \mathbf{s}_t) } \left[ Q^\pi (\mathbf{s}_t, \mathbf{a}_t ) \right] \end{align} \]
같은 방법을 행동가치 함수와 벨만 방정식에도 적용하면 각각 다음과 같이 된다.
\[ \begin{align} Q^\pi (\mathbf{s}_t, \mathbf{a}_t ) &= r_t + \sum_{\mathbf{s}_{t+1} \in \mathcal{S}} \gamma V^\pi (\mathbf{s}_{t+1}) p ( \mathbf{s}_{t+1} | \mathbf{s}_t, \mathbf{a}_t ) \\ \\ &= r_t + \mathbb{E}_{ \mathbf{s}_{t+1} \sim p (\mathbf{s}_{t+1} | \mathbf{s}_t, \mathbf{a}_t) } \left[ \gamma V^\pi (\mathbf{s}_{t+1} ) \right] \end{align} \]
\[ \begin{align} V^\pi (\mathbf{s}_t) &= \sum_{\mathbf{a}_t \in \mathcal{A}} \left[ r_t + \sum_{\mathbf{s}_{t+1} \in \mathcal{S}} \gamma V^\pi (\mathbf{s}_{t+1}) p ( \mathbf{s}_{t+1} | \mathbf{s}_t, \mathbf{a}_t ) \right] \pi (\mathbf{a}_t | \mathbf{s}_t) \\ \\ &= \mathbb{E}_{ \mathbf{a}_t \sim \pi (\mathbf{a}_t | \mathbf{s}_t) } \left[ r_t + \mathbb{E}_{ \mathbf{s}_{t+1} \sim p (\mathbf{s}_{t+1} | \mathbf{s}_t, \mathbf{a}_t ) } \left[ \gamma V^\pi (\mathbf{s}_{t+1} ) \right] \right] \end{align} \]
\[ \begin{align} Q^\pi (\mathbf{s}_t, \mathbf{a}_t ) &= r_t + \sum_{\mathbf{s}_{t+1} \in \mathcal{S}} \gamma \left[ \sum_{\mathbf{a}_{t+1} \in \mathcal{A}} Q^\pi (\mathbf{s}_{t+1}, \mathbf{a}_{t+1} ) \pi (\mathbf{a}_{t+1} | \mathbf{s}_{t+1}) \right] p ( \mathbf{s}_{t+1} | \mathbf{s}_t, \mathbf{a}_t ) \\ \\ &= r_t + \mathbb{E}_{ \mathbf{s}_{t+1} \sim p (\mathbf{s}_{t+1} | \mathbf{s}_t, \mathbf{a}_t) } \left[ \mathbb{E}_{ \mathbf{s}_{t+1} \sim p (\mathbf{s}_{t+1} | \mathbf{s}_t, \mathbf{a}_t) } \left[ \gamma Q^\pi (\mathbf{s}_{t+1}, \mathbf{a}_{t+1} ) \right] \right] \end{align} \]
여기서 \(p ( \mathbf{s}_{t+1} | \mathbf{s}_t, \mathbf{a}_t )\)는 조건부 확률을 뜻한다.
'AI 딥러닝 > RL' 카테고리의 다른 글
| 정책 이터레이션 (Policy Iteration) (0) | 2021.04.29 |
|---|---|
| 벨만 최적 방정식 (Bellman Optimality Equation) (0) | 2021.04.28 |
| 가치함수 (Value Function) (0) | 2021.04.21 |
| Tensorflow2로 만든 A2C 코드: Pendulum-v0 (0) | 2021.04.20 |
| A2C 알고리즘-2: 액터 신경망 (0) | 2021.04.20 |




댓글