강화학습에서 에이전트(agent)가 최대화해야 할 누적 보상의 기댓값 또는 목적함수는 다음과 같다.
\[ J(\theta)= \mathbb{E}_{\tau \sim p_\theta (\tau)} \left[ \sum_{t=0}^T \gamma^t r_t (\mathbf{x}_t, \mathbf{u}_t ) \right] \]
여기서 \(p_\theta (\tau)\)는 정책 \(\pi_\theta (\mathbf{u}_t | \mathbf{x}_t )\)로 생성되는 궤적의 확률밀도함수이다.
목적함수를 최대화하는 파라미터 \(\theta\)는 다음과 같이 경사상승법으로 구할 수 있다.
\[ \theta \gets \theta + \alpha \nabla_\theta J(\theta) \]
경사상승법 또는 이로부터 파생된 최적화 방법을 사용하기 위해서는 목적함수의 그래디언트 \(\nabla_\theta J(\theta)\)가 필요하다. 목적함수가 \(\theta\)의 함수인 이유는 정책 \(\pi_\theta (\mathbf{u}_t | \mathbf{x}_t )\)가 \(\theta\)로 파라미터화 됐기 때문이므로 목적함수의 그래디언트는 곧 정책 그래디언트와 관련이 있다.

목적함수의 그래디언트를 전개할 때, 현재 실행된 정책은 과거의 보상에 영향을 미치지 못한다는 점(인과성, causality)을 고려하고 행동가치(action-value) 함수 \(Q^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t )\)의 정의를 이용하면 그래디언트는 다음과 같이 된다(유도 과정 생략).
\[ \nabla_\theta J(\theta)= \sum_{t=0}^T \left( \mathbb{E}_{\mathbf{x}_t \sim p_\theta (\mathbf{x}_t ), \mathbf{u}_t \sim \pi_\theta (\mathbf{u}_t | \mathbf{x}_t) } \left[ ( \nabla_\theta \log \pi_\theta (\mathbf{u}_t | \mathbf{x}_t) ) Q^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t ) \right] \right) \]
베이스라인으로서 상태가치(state-value) 함수 \(V^{\pi_\theta} (\mathbf{x}_t) \)를 도입하여 위 식에 대입하면 그래디언트를 다음과 같이 바꿀 수 있다(유도 과정 생략).
\[ \nabla_\theta J(\theta)= \sum_{t=0}^T \left( \mathbb{E}_{\mathbf{x}_t \sim p_\theta (\mathbf{x}_t ), \mathbf{u}_t \sim \pi_\theta (\mathbf{u}_t | \mathbf{x}_t) } \left[ ( \nabla_\theta \log \pi_\theta (\mathbf{u}_t | \mathbf{x}_t) ) A^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t ) \right] \right) \]
여기서 \(A^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t ) = Q^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t )- V^{\pi_\theta} (\mathbf{x}_t )\)를 어드밴티지(advantage)함수라고 한다. 두 식의 차이점은 행동가치 대신에 어드밴티지를 사용한다는 것이고 이를 통해 그래디언트의 분산이 작아질 것을 기대하는 것이다.
행동가치는 상태변수 \( \mathbf{x}_t\)에서 선택 가능한 모든 행동 \( \mathbf{u}_t\)에 대한 행동가치의 평균값이므로, 즉 \(V^\pi (\mathbf{x}_t )= \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t)} \left[ Q^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right]\)이므로 어드밴티지 함수는 상태변수 \(\mathbf{x}_t\)에서 선택된 행동 \(\mathbf{u}_t\)가 평균에 비해 얼마나 좋은지를 평가하는 척도로 해석할 수 있다.
행동가치와 상태가치 함수에 관한 벨만 방정식은 다음과 같으므로
\[ Q^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t ) = r(\mathbf{x}_t, \mathbf{u}_t ) + \mathbb{E}_{\mathbf{x}_{t+1} \sim p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t) } \left[ \gamma V^{\pi_\theta} (\mathbf{x}_{t+1} ) \right] \]
어드밴티지 함수는 다음과 같이 상태가치 함수를 이용하여 표현할 수 있다.
\[ A^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t ) = r(\mathbf{x}_t, \mathbf{u}_t ) + \mathbb{E}_{\mathbf{x}_{t+1} \sim p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t) } \left[ \gamma V^{\pi_\theta} (\mathbf{x}_{t+1} ) \right] - V^{\pi_\theta} (\mathbf{x}_t) \]
정리하면, 목적함수를 최대화하는 파라미터 \(\theta\)를 구하기 위해서 다음 식을 이용하여 목적함수의 그래디언트를 계산하고,
\[ \nabla_\theta J(\theta)= \sum_{t=0}^T \left( \mathbb{E}_{\mathbf{x}_t \sim p_\theta (\mathbf{x}_t ), \mathbf{u}_t \sim \pi_\theta (\mathbf{u}_t | \mathbf{x}_t) } \left[ ( \nabla_\theta \log \pi_\theta (\mathbf{u}_t | \mathbf{x}_t) ) A^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t ) \right] \right) \]
다음과 같이 경사상승법으로 파라미터 \(\theta\)를 업데이트 한다.
\[ \theta \gets \theta + \alpha \nabla_\theta J(\theta) \]
그런데 여기서 수식에 있는 함수들을 에이전트가 모르기 때문에, 정책을 실행해서 발생시킨 데이터, 즉 샘플 궤적을 이용해서 그래디언트를 계산해야 할 필요가 있다.
위 식에서 기댓값은 에피소드 평균값으로 근사화할 수 있다.
\[ \nabla_\theta J(\theta) \approx \frac{1}{M} \sum_{m=1}^M \sum_{t=0}^T \left[ (\nabla_\theta \log \pi_\theta (\mathbf{u}_t^{(m)} | \mathbf{x}_t^{(m)} )) A^{\pi_\theta} (\mathbf{x}_t^{(m)}, \mathbf{u}_t^{(m)} ) \right] \]
여기서 \(m\)은 에피소드 인덱스이며, \(M\)은 에피소드 개수이다.

에피소드의 평균값으로 근사화하는 것에 비해 정확도는 못미치지만 한 개의 샘플만을 이용해서 목적함수의 그래디언트를 근사화 할 수도 있다.
\[ \nabla_\theta J(\theta) \approx \sum_{t=0}^T \left[ (\nabla_\theta \log \pi_\theta (\mathbf{u}_t^{(m)} | \mathbf{x}_t^{(m)} )) A^{\pi_\theta} (\mathbf{x}_t^{(m)}, \mathbf{u}_t^{(m)} ) \right] \]

하지만 위 식으로 그래디언트를 계산하려고 해도 수식 안에 있는 어드밴티지 함수 \(A^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t )\)를 알아야 하는데, 이 역시 알지 못하므로 데이터를 이용하여 추정할 수밖에 없다.
어드밴티지 함수가 다음 식으로 주어지므로
\[ A^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t )= r(\mathbf{x}_t, \mathbf{u}_t )+ \mathbb{E}_ { \mathbf{x}_{t+1} \sim p(\mathbf{x}_{t+1 } | \mathbf{x}_t, \mathbf{u}_t) } \left[ \gamma V^{\pi_\theta} (\mathbf{x}_{t+1} ) \right]-V^{\pi_\theta} (\mathbf{x}_t) \]
한 개의 샘플만을 이용한다면 어드밴티지는 다음과 같이 근사적으로 계산할 수 있다.
\[ A^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t ) \approx r(\mathbf{x}_t, \mathbf{u}_t )+ \gamma V^{\pi_\theta} (\mathbf{x}_{t+1} ) -V^{\pi_\theta} (\mathbf{x}_t) \]
이제 상태가치 함수를 계산할 수 있으면 되는데, 데이터를 이용하여 계산 방법을 고안해 보자. 이를 위해서 먼저 상태가치 함수의 관계식이 필요하다.
벨만 방정식에 의하면 현재 상태와 다음 상태의 가치 함수는 다음과 같은 관계가 있다.
\[ \begin{align} V^{\pi_\theta} (\mathbf{x}_t) & = \mathbb{E}_{ \mathbf{u}_t \sim \pi_\theta (\mathbf{u}_t | \mathbf{x}_t) } \left[ r(\mathbf{x}_t, \mathbf{u}_t )+ \mathbb{E}_ { \mathbf{x}_{t+1} \sim p(\mathbf{x}_{t+1 } | \mathbf{x}_t, \mathbf{u}_t) } \left[ \gamma V^{\pi_\theta} (\mathbf{x}_{t+1} ) \right] \right] \\ \\ & \approx r(\mathbf{x}_t, \mathbf{u}_t )+ \gamma V^{\pi_\theta} (\mathbf{x}_{t+1} ) \end{align} \]
상태가치 함수를 추정하기 위해서 정책 신경망과는 다른 신경망을 이용하기로 하고, 그 신경망의 파라미터를 \(\phi\)로 표기하며 추정된 상태가치를 \(V_\phi (\mathbf{x}_t)\)라고 하자. 이 신경망을 크리틱(critic) 신경망이라고 한다. 크리틱 신경망은 상태변수를 입력으로 받으며 그 상태에 대한 상태가치 값이 출력된다.
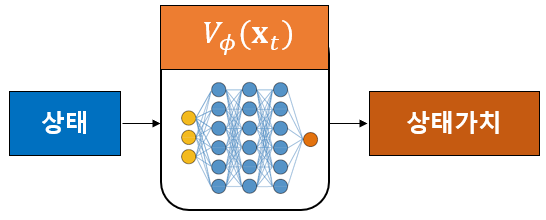
이 신경망의 손실함수는 상태가치 함수를 정확히 추정할 수 있는 최적의 파라미터 \(\phi\)를 갖도록 정해져야 한다. 따라서 손실함수는 상태가치 추정값 \(V_\phi (\mathbf{x}_t)\)과 상태가치의 참값 \(V^{\pi_\theta} (\mathbf{x}_t )\)의 차이가 최소가 되도록 정하면 될 것 같다.
일반적인 지도학습(supervised learning) 문제이므로 신경망의 입력과 그 입력에 대한 정답으로 학습 데이터셋 \(\left( \mathbf{x}_i, V^{\pi_\theta} (\mathbf{x}_i ) \right) \)를 모으고 손실함수를 다음과 같이 평균제곱오차(MSE, mean squared error)로 정한다.
\[ L(\phi)= \frac{1}{2} \sum_i \lVert V^{\pi_\theta} (\mathbf{x}_i )- V_\phi (\mathbf{x}_i ) \rVert^2 \]
그런데 여기서 상태가치의 참값 \( V^{\pi_\theta} (\mathbf{x}_i ) \)를 알지 못하므로, 참값 대신 추정값을 사용한다. 이와 같이 참값 대신 추정값을 사용하는 방법을 부트스트래핑(bootstrapping)이라고 한다.
\[ \begin{align} V^{\pi_\theta} (\mathbf{x}_i) & \approx r(\mathbf{x}_i, \mathbf{u}_i )+ \gamma V^{\pi_\theta} (\mathbf{x}_{i+1} ) \\ \\ & \approx r(\mathbf{x}_i, \mathbf{u}_i )+ \gamma V_\phi (\mathbf{x}_{i+1} ) \end{align} \]
그러면 손실함수는 다음과 같이 된다.
\[ L(\phi)= \frac{1}{2} \sum_i \lVert y_i - V_\phi (\mathbf{x}_i ) \rVert^2 \]
여기서 \(y_i= r(\mathbf{x}_i, \mathbf{u}_i )+ \gamma V^{\pi_\theta} (\mathbf{x}_{i+1} )\)를 시간차 타깃이라고 한다.

손실함수를 최소화하는 파라미터 \(\phi\)는 다음과 같이 경사하강법으로 구할 수 있다.
\[ \phi \gets \phi -\alpha_\phi \nabla_\phi L(\phi) \]
손실함수의 그래디언트는 다음과 같이 계산한다.
\[ \nabla_\phi L(\phi) = - \sum_i \left( y_i- V_\phi (\mathbf{x}_i ) \right) \nabla_\phi V_\phi (\mathbf{x}_i ) \]
그런데 여기서 잠시 생각해야할 문제가 있다. 크리틱 신경망의 파라미터 \(\phi\)를 계산하는 과정이 일반적인 지도학습과 겉보기에 같아 보이지만 사실은 다르다는 점이다. 일반적인 지도학습에서는 타깃이 신경망이 산출해야 할 참값으로 주어지며 그 값은 신경망 파라미터와 무관하게 일정한 값으로 주어진다. 하지만 여기서는 타깃이 파라미터 \(\phi\)의 함수다. 시간차 타깃 \(y_i\)에 있는 상태가치 추정값 \(V_\phi (\mathbf{x}_{t+1})\) 때문이다.
따라서 타깃은 크리틱 신경망을 업데이트 할 때 마다 계속 달라지며, 달라지는 타깃을 따라가며 신경망을 계속 업데이트 해야 하므로 학습이 불안정해질 수 있다.
본래 상태가치 함수의 정의에 의하면, 상태가치 함수 \(V^{\pi_\theta} (\mathbf{x}_t )\)는 상태변수 \(\mathbf{x}_t\)에서 정책 \(\pi_\theta\)로 기대할 수 있는 미래 보상의 총합이다. 정책이 일정하다면 같은 상태변수에서 기대할 수 있는 미래 보상의 총합은 일정해야 한다. 즉 타깃은 크리틱 신경망의 파라미터와 무관하게 일정해야 한다. 하지만 크리틱 신경망을 학습할 때 부트스트래핑을 사용하기 때문에 이런 일이 발생하게 되었다.
그리고 손실함수의 그래디언트를 계산할 때도 문제다. 시간차 타깃 \(y_i\)도 \(\phi\)의 함수이기 때문에 손실함수의 그래디언트는 본래 다음과 같이 계산해야 맞다.
\[ \nabla_\phi L(\phi) = - \sum_i \left( y_i- V_\phi (\mathbf{x}_i ) \right) \left( \nabla_\phi V_\phi (\mathbf{x}_i ) - \gamma \nabla_\phi V_\phi (\mathbf{x}_{i+1} ) \right) \]
이와 같은 계산 방법을 Residual Gradient 알고리즘이라고 한다. 하지만 Residual Gradient 알고리즘은 수치적인 문제 때문에 잘 사용하지 않는다.
결론적으로 크리틱 신경망의 학습 시 크리틱 신경망의 파라미터가 일정한 값으로 수렴한다는 보장은 없다.
이제 업데이트 된 \(V_{\phi_new} (\mathbf{x}_t )\)를 이용하여 어드밴티지 함수를 다음과 같이 계산하면 된다.
\[ A^{\pi_\theta} (\mathbf{x}_t, \mathbf{u}_t ) \approx \hat{A} (\mathbf{x}_t, \mathbf{u}_t ) = r( \mathbf{x}_t, \mathbf{u}_t )+ \gamma V_{\phi_{new}} (\mathbf{x}_{t+1} )-V_{\phi_{new}} (\mathbf{x}_t ) \]
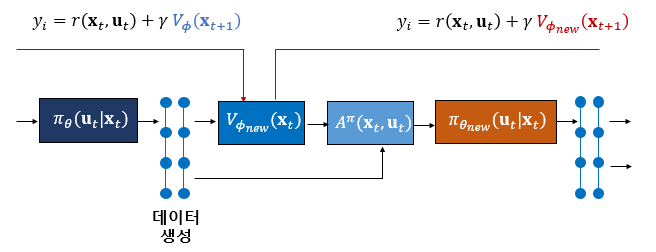
만약 학습 중에 크리틱 신경망의 파라미터가 점진적으로 업데이트된다고 가정한다면 업데이트된 \(V_{\phi_{new}} (\mathbf{x}_t )\)와 업데이트 직전의 \(V_{\phi} (\mathbf{x}_t )\)의 차이가 크지 않을 것으로 생각할 수 있으므로 어드밴티지 함수를 다음과 같이 계산할 수도 있다.
\[ \hat{A} (\mathbf{x}_t, \mathbf{u}_t ) = r( \mathbf{x}_t, \mathbf{u}_t )+ \gamma V_\phi (\mathbf{x}_{t+1} )-V_\phi (\mathbf{x}_t ) \]
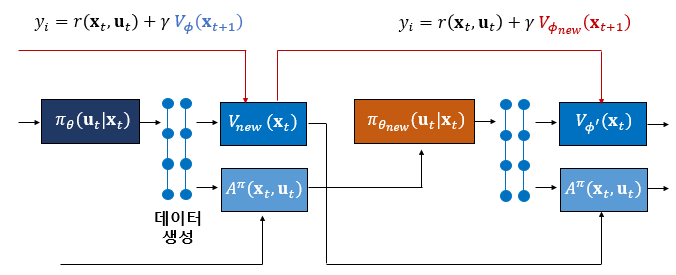
다음에는 크리틱 신경망에 이어서 행동을 산출하는 액터 신경망에 대해서 알아본다.
'AI 딥러닝 > RL' 카테고리의 다른 글
| Tensorflow2로 만든 A2C 코드: Pendulum-v0 (0) | 2021.04.20 |
|---|---|
| A2C 알고리즘-2: 액터 신경망 (0) | 2021.04.20 |
| 정책 그래디언트 기반 강화학습의 원리 (0) | 2021.04.13 |
| 강화학습 문제 (0) | 2020.11.08 |
| 강화학습의 한계 (0) | 2020.10.28 |




댓글