고전 적합직교분해(classical POD)는 공간은 이산화시켰지만 시간은 연속적이다. 하지만 실제 유체역학이나 구조해석 문제의 경우 벡터 필드는 일정한 시간 간격의 싯점에서 수치해석으로 계산된 데이터나 또는 측정된 데이터로 주어진다.
고전 POD의 또 다른 문제점은 차원이 \(n=10^8 \sim 10^{10}\)에 달하는 매우 고차원 행렬의 고유값과 고유벡터를 계산해야 하는데 있다. 이 정도 규모의 차원에서 이를 계산하는 것은 거의 불가능하다. 이러한 고전 POD의 단점을 극복하기 위한 방안으로 스냅샷(snapshot) POD가 개발되었다.
스냅샷 POD는 벡터 필드의 공간 뿐만 아니라 시간도 이산화시켰다는 데 특징이 있다. 스냅샷이란 일정한 싯점에서 수집한 데이터의 집합을 뜻한다.
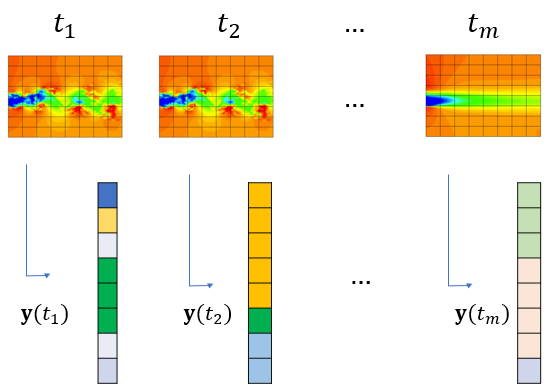
먼저 벡터 필드 \(\mathbf{q}(\mathbf{p},t)\)의 값을 전체 그리드 포인트 \(\mathbf{p}_j\)에서 시간 \(t=t_1, t_2, ..., t_m\) 마다 수집하여 스냅샷 데이터 벡터 \(\mathbf{y}(t_i ) \in \mathbb{R}^n\) 로 만든다.
\[ \mathbf{y}(t_i)= \begin{bmatrix} \mathbf{q}(\mathbf{p}_1, t_i) - \bar{\mathbf{q}}(\mathbf{p}_1) \\ \vdots \\ \mathbf{q}(\mathbf{p}_N, t_i) - \bar{\mathbf{q}}(\mathbf{p}_N) \end{bmatrix} , \ \ \ i=1, ..., m \]
여기서 \(\bar{\mathbf{q}}(\mathbf{p}_j )\)는 벡터 필드의 시간 평균을 뜻한다. 따라서 벡터 \(\mathbf{y}(t_i )\)는 시간 평균을 기준으로 변동하는 벡터 필드의 성분(unsteady component)을 나타낸다.
적합직교분해(POD)는 n차원 공간상에서 \(d\)개의 POD 모드 \(\mathbf{w}_1, \mathbf{w}_2, ..., \mathbf{w}_d\)로 구성된 부분 공간에 벡터 \(\mathbf{y}(t)\)를 투사(projection)할 때 투사 오차가 최소가 되도록 POD 모드(mode)를 결정하는 방법이다.
벡터 \(\mathbf{y}(t_i)\)를 \(d\)개의 좌표축으로 이루어진 부분 공간으로 투사하면 다음과 같다.
\[ \begin{align} \mathbf{y}(t_i ) & \approx \sum_{j=1}^d a_j (t_i ) \mathbf{w}_j \\ \\ &= \begin{bmatrix} \mathbf{w}_1 & \mathbf{w}_2 & \cdots & \mathbf{w}_d \end{bmatrix} \begin{bmatrix} a_1(t_i) \\ a_2(t_i) \\ \vdots \\ a_d(t_i) \end{bmatrix} \\ \\ &= W \mathbf{a}(t_i) \end{align} \]
여기서 \(a_j (t_i)\)는 \(\mathbf{y}(t_i)\)의 \(\mathbf{w}_j\)축 성분으로서 \(a_j (t_i)=\mathbf{w}_j^T \mathbf{y}(t_i)\)로 주어지며,
\[ \mathbf{a}(t_i)=W^T \mathbf{y}(t_i) \]
이다. \( W \in \mathbb{R}^{n \times d}\)는 서로 직각인 단위 벡터(orthonormal vectors)로 이루어진 행렬로서 다음 식을 만족한다.
\[ W^T W=I_d \]
앞서 고전 POD 문제를 다음과 같은 최적화 문제로 정식화했었는데,
\[ \begin{align} & \arg\min_W J = \int_0^T \lVert \mathbf{y} (t) - WW^T \mathbf{y}(t) \rVert_2^2 \ dt \\ \\ & \mbox{subject to} \ \ \ W^T W=I_d \end{align} \]
스냅샷 POD에서는 시간도 이산화 됐으므로 다음과 같이 최적화 문제를 바꿔야 한다.
\[ \begin{align} & \arg\min_W J = \sum_{i=1}^m \lVert \mathbf{y} (t_i) - WW^T \mathbf{y}(t_i) \rVert_2^2 \\ \\ & \mbox{subject to} \ \ \ W^T W=I_d \end{align} \]
시간 영역 \(t=[0, T]\)에서 \(m\)개의 스냅샷 데이터 \(\mathbf{y}(t_i )\)를 수집하여 이를 다음과 같이 행렬 형태로 쓰면,
\[ Y = \begin{bmatrix} \mathbf{y}(t_1) & \mathbf{y}(t_2) & \cdots & \mathbf{y}(t_m) \end{bmatrix} \ \in \mathbb{R}^{n \times m} \]
최적화 문제를 다음과 같이 표현할 수 있다.
\[ \begin{align} & \arg\min_W J = trace \left[ (Y-WW^TY)^T (Y-WW^TY) \right] \\ \\ & \mbox{subject to} \ \ \ W^T W=I_d \end{align} \]
고전 POD 알고리즘을 유도할 때에도 PCA의 그림자가 어른거렸을 텐데, 스냅샷 POD 문제에 이르러서는 PCA에서 풀려고 하는 문제와 완벽히 일치한다는 것을 알아챘을 것이다.
사실 주성분 분석(PCA)과 적합직교분해(POD)는 동일한 알고리즘이다. 적용되는 분야에 따라서 각각 다른 명칭으로 불려진 것 뿐이다. 항공우주공학이나 기계공학 분야에서는 POD라는 용어가, 데이터 사이언스나 통계 분야에서는 PCA라는 용어가 주로 사용된다. 그 밖에 신호처리에서는 카루넨-뢰브 변환 (Karhunen-Loeve transform), 경제학이나 심리학 분야에서는 인자분석(factor analysis) 등의 표현으로 불린다.
여기서는 POD 알고리즘을 또다시 유도할 필요는 없을 것 같고, PCA에서 유도된 과정을 간단히 정리하는 것으로 대신하려고 한다.
(1) 스냅샷 행렬 \(Y\)의 특이값 분해(SVD, singular value decomposition)를 계산한다.
\[ \begin{align} & Y= U \Sigma V^T \\ \\ & U= \begin{bmatrix} \mathbf{u}_1 & \cdots & \mathbf{u}_n \end{bmatrix} \in \mathbb{R}^{n \times n}, \ V= \begin{bmatrix} \mathbf{v}_1 & \cdots & \mathbf{v}_m \end{bmatrix} \in \mathbb{R}^{m \times m} \end{align} \]
(2) \(d\)차원 (\(d \lt n\)) POD 모드 \(\mathbf{w}_i, i= 1, ..., d\) 를 선택한다.
\[ \begin{align} W &= \begin{bmatrix} \mathbf{w}_1 & \mathbf{w}_2 & \cdots & \mathbf{w}_d \end{bmatrix} \\ \\ &= \begin{bmatrix} \mathbf{u}_1 & \mathbf{u}_2 & \cdots & \mathbf{u}_d \end{bmatrix} = U_d \ \in \mathbb{R}^{n \times d} \end{align} \]
(3) POD 모드 \(\mathbf{w}_j, i=1, ..., d\) 의 성분은 다음과 같이 계산한다.
\[ a_j (t_i)= \mathbf{w}_j^T \mathbf{y}(t_i) \]
(4) 고차원 벡터 필드는 다음과 같이 복원시킬 수 있다.
\[ \begin{bmatrix} \hat{\mathbf{q}} (\mathbf{p}_1, t_i) \\ \vdots \\ \hat{\mathbf{q}} (\mathbf{p}_N, t_i) \end{bmatrix} =\begin{bmatrix} \bar{\mathbf{q}} (\mathbf{p}_1) \\ \vdots \\ \bar{\mathbf{q}} (\mathbf{p}_N) \end{bmatrix} + \sum_{j=1}^d a_j(t_i) \mathbf{w}_j \]
앞서 언급했듯이 고차원 (\(m \ll n\))에서는 (1)번의 특이값 분해(SVD)가 거의 불가능하다.
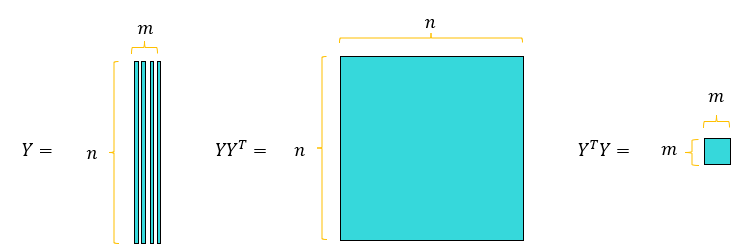
따라서 위 알고리즘을 다음과 같이 수정한다.
(1) 행렬 \(Y^T Y \in \mathbb{R}^{m \times m}\)의 고유값 \(\sigma_i^2\)과 고유벡터 \(\mathbf{v}_i\)를 계산한다.
\[ Y^T Y \mathbf{v}_i= \sigma_i^2 \mathbf{v}_i, \ \ i=1, ..., m \]
(2) 스냅샷 행렬 \(Y\)의 왼쪽 특이벡터 \(\mathbf{u}_i\)를 계산한다.
\[ \mathbf{u}_i= \frac{Y \mathbf{v}_i}{\sigma_i }, \ \ \ i=1, ..., m \]
(3) \(d\)차원 (\(d \lt n\)) POD 모드 \(\mathbf{w}_i, i= 1, ..., d\) 를 선택한다.
\[ \begin{align} W &= \begin{bmatrix} \mathbf{w}_1 & \mathbf{w}_2 & \cdots & \mathbf{w}_d \end{bmatrix} \\ \\ &= \begin{bmatrix} \mathbf{u}_1 & \mathbf{u}_2 & \cdots & \mathbf{u}_d \end{bmatrix} = U_d \ \in \mathbb{R}^{n \times d} \end{align} \]
(4) POD 모드 \(\mathbf{w}_j, i=1, ..., d\) 의 성분은 다음과 같이 계산한다.
\[ a_j (t_i)= \mathbf{w}_j^T \mathbf{y}(t_i) \]
(5) 고차원 벡터 필드는 복원시킨다.
\[ \begin{bmatrix} \hat{\mathbf{q}} (\mathbf{p}_1, t_i) \\ \vdots \\ \hat{\mathbf{q}} (\mathbf{p}_N, t_i) \end{bmatrix} =\begin{bmatrix} \bar{\mathbf{q}} (\mathbf{p}_1) \\ \vdots \\ \bar{\mathbf{q}} (\mathbf{p}_N) \end{bmatrix} + \sum_{j=1}^d a_j(t_i) \mathbf{w}_j \]
'유도항법제어 > 데이터기반제어' 카테고리의 다른 글
| [POD-4] Gappy POD 매트랩 예제 (0) | 2021.03.01 |
|---|---|
| [POD-3] 개피 적합직교분해 (gappy POD) (0) | 2021.03.01 |
| [POD-1] 고전 적합직교분해 (classical POD) (0) | 2021.02.28 |
| [PCA–4] PCA 예제: Eigenfaces (0) | 2021.02.24 |
| [PCA–3] 주성분 분석 (PCA) 특징 (0) | 2021.02.20 |




댓글