최적제어 문제는 다음과 같이 이산시간(discrete-time) 차분 방정식(difference equation)으로 표현된 비선형 시스템이 있을 때,
\[ \mathbf{x}_{t+1} = \mathbf{f}_t ( \mathbf{x}_t, \mathbf{u}_t) \]
시스템이 어떤 스칼라 성능지수(performance index) \( J_i \)를 최소화하도록 제어변수 \( \mathbf{u}_t \in R^m \)를 결정하는 문제다. 성능지수의 일반적인 형태는 다음과 같다.
\[ J_i = \phi (T, \mathbf{x}_T )+ \sum_{t=i}^{T-1} g_t ( \mathbf{x}_t, \mathbf{u}_t) \]
여기서 아래 첨자 \(t \)는 시간스텝을 나타내며 \( \mathbf{x}_t \in R^n \)는 상태변수는, \( [i, T] \)는 관심 시간 구간, \( \phi \)는 최종 상태변수와 최종 시간에 부과되는 최종 성능함수이고, \( g_t (\mathbf{x}_t, \mathbf{u}_t) \)는 관심 시간 구간 전체에 부과되는 운행 성능함수이다.
반면에 강화학습(reinforcement learning) 문제는 어떤 에이전트(agent)가 환경(environment)이 주는 누적 보상(reward)의 기댓값을 최대화하기 위해서 시간 순서대로 환경에 가해지는 행동(action)을 결정하는 문제다. 누적 보상의 기댓값 또는 성능지수는 다음과 같이 주어진다.
\[ J_i= \mathbb{E}_{\tau \sim p(\tau)} \left[ \sum_{t=i}^T \gamma^{t-i} r_t ( \mathbf{s}_t, \mathbf{a}_t) \right] \]
여기서 \( [i, T] \)는 관심 시간 구간, \( \mathbf{s}_t \in R^n \)은 환경의 상태변수, \( \mathbf{a}_t \in R^m \)은 에이전트의 행동, \( \gamma \in [0, 1] \)는 감가율(discount factor), \( r_t \)는 시간스텝 \( t \)일 때 상태변수 \( \mathbf{s}_t \)에서 행동 \( \mathbf{a}_t \)를 가했을 때 에이전트가 받는 보상을 나타내는 보상함수다.
기댓값 \( \mathbb{E} \)의 아래 첨자 \( p(\tau) \)는 기댓값을 계산할 때 확률밀도함수로 \( p(\tau) \)를 사용한다는 의미다. \(\tau \)는 상태변수와 행동의 시퀀스로 이루어진 궤적 \(\tau =( \mathbf{s}_i, \mathbf{a}_i, \mathbf{s}_{i+1}, \mathbf{a}_{i+1}, ..., \mathbf{s}_T, \mathbf{a}_T ) \)을 나타낸다.
강화학습에서는 보통 상태변수와 행동을 랜덤변수로 가정하기 때문에 보상도 랜덤변수가 되므로 누적 보상함수를 항상 최대화할 수 있는 행동 시퀀스를 구할 수는 없다. 대신에 누적 보상함수의 기댓값을 최대로 만드는 행동 시퀀스를 구하는 것을 목적으로 한다.
에이전트는 환경의 변화를 표현하는 상태를 관측(observation)하여 일정한 정책(policy)하에 불연속적인 값이나 연속적인 값으로 된 행동을 선택(의사 결정)하며, 이를 환경에 인가해 환경을 변화시킨다. 그리고 그 결과로 시간스텝마다 또는 간헐적으로 의사 결정 성과를 평가하는 보상을 제공받는다. 행동의 선택이 종료되는 시점까지 누적된 총 보상을 최대화하면 원하는 목표가 성취되는 것으로 본다.
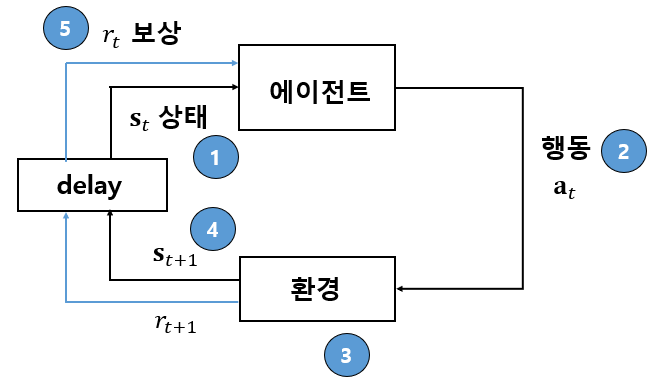
강화학습에서는 환경이 보상을 제공한다고 가정한다. 그러나 실제로는 강화학습 설계자가 에이전트가 원하는 반응을 보이도록 보상함수를 설계해야 한다. 성능지수를 최대화하는 행동이 환경을 설계자가 원하는 대로 이상적으로 움직이게 한다는 뜻이 아니다. 따라서 성능지수를 최대화하면 설계자가 원하는 대로 환경이 바뀌거나 성능이 고도화되도록 잘 선정할 필요가 있다.
강화학습 문제는 최적제어에서 다루는 문제와 유사하다. 사용하는 용어에서는 몇 가지 차이가 있다. 최적제어에서의 제어법칙(control law)을 강화학습에서는 정책이라고 하며, 제어기(controller)를 에이전트, 제어변수를 행동, 시스템의 동역학을 환경이라고 한다. 최적제어에서는 성능지수를 비용(cost)의 누적합으로 설정하고 강화학습에서는 보상(reward)의 누적합으로 설정한다. 따라서 최적제어에서는 성능지수를 최소화하려고 하며, 강화학습에서는 최대화하려고 한다.
기호에서도 차이가 있는데 최적제어에서 상태변수는 \( \mathbf{x}_t \), 강화학습에서는 \( \mathbf{s}_t \)로 표기하고 제어입력은 \( \mathbf{u}_t \), 행동은 \( \mathbf{a}_t \)로 표기한다.
최적제어와 강화학습의 결정적인 차이점은 정확한 시스템 동역학 모델의 유무에 있다. 시스템의 동역학 모델이 있다면 시스템에 제어입력을 인가했을 때 시스템의 반응을 정확히 알 수 있다. 최적제어는 동역학 모델을 이용하여 최적제어 법칙을 수학적으로 유도해 낼 수 있다.
반면에, 강화학습에서는 환경의 수학적 모델이 없으므로 환경에 행동을 인가했을 때 환경이 어떻게 반응할 지 알 수 없다. 따라서 수많은 시행착오법을 통해서 환경의 반응을 유추하든가 아니면 어떤 행동이 큰 보상을 얻는데 유리한가를 학습해야 한다. 즉, 환경에 행동을 가해서 데이터를 생성하고 이를 수집해서 환경 모델이나 성능지수를 추정하여 행동을 재설정하는 반복과정을 거쳐야 한다.
'AI 딥러닝 > RL' 카테고리의 다른 글
| Tensorflow2로 만든 A2C 코드: Pendulum-v0 (0) | 2021.04.20 |
|---|---|
| A2C 알고리즘-2: 액터 신경망 (0) | 2021.04.20 |
| A2C 알고리즘-1: 크리틱 신경망 (0) | 2021.04.20 |
| 정책 그래디언트 기반 강화학습의 원리 (0) | 2021.04.13 |
| 강화학습의 한계 (0) | 2020.10.28 |




댓글