강화학습에서는 보상(reward)을 환경이 제공한다고 가정하지만 실제로는 강화학습 설계자가 시스템이 원하는 반응을 보이도록 보상함수를 설계해야 한다. 보상함수는 설계자가 원하는 것을 정확히 포착하도록 해야 하지만, 학습의 안정성과 효율성도 고려해서 신중하게 설계해야 한다. 강화학습을 실제 문제에 적용하는데 있어서 어려운 점 중의 하나는 바로 이 보상함수를 적절하게 설계하는 것이다.
특히 항공기나 미사일, 그리고 로봇과 같은 물리 시스템의 경우에는 도메인 지식이 없거나 또는 복잡하고 예측할 수 없는 환경에서는 적절한 보상을 설정하는 것 자체가 어려울 수도 있고, 또한 잘못된 지표를 최적화하게 되면 실제 의도한 목표에 대한 성능이 저하됨은 물론 예상하지 못한 원치 않는 동작을 유발할 수도 있다.
따라서 설계자가 원하는 행동을 적절하게 학습하고 원하는 목표를 성공적으로 달성하게 만드는 강화학습 에이전트의 보상함수 설계에 관한 문제는 계속 연구 대상이 되고 있다.
OpenAI의 논문 "Hindsight Experience Replay" 에서도 보상함수에 관한 문제를 다루고 있다. 이 논문에서는 희소(sparse) 바이너리(binary) 보상이 주어지는 환경에서 효율적인 학습 방법을 제시하고 있다. 희소 바이너리 보상이 주어지는 환경의 예로는 바둑과 같은 게임에서 이길 때에만 보상이 주어지는 경우를 들 수 있다. 또한 미사일의 적 항공기 요격 학습 환경에서 미사일이 적기를 요격에 성공할 때만 보상이 주어지는 경우도 들 수 있겠다.
보통 에피소드 중에 중간 보상이 없으면 대부분의 경우 학습이 매우 어려워진다. 에이전트가 환경을 적절하게 탐색하고 성능을 개선하는 방법에 대한 피드백을 충분히 받지 못하기 때문이다. 이 때 자주 사용되는 실용적인 방법은 도메인 지식을 사용하여 중간 보상을 생성하는 것이다. 이런 방법을 보상공학(reward engineering) 또는 보상성형(reward shaping)이라고 한다.
논문 HER (Hindsight Experience Replay)에서는 이러한 보상공학을 사용하지 않고도 희소 바이너리 보상이 주어지는 환경에서의 학습 문제를 해결하는 간단한 방법을 제시한다. 이 방법은 인간이 실패의 경험에서도 학습하는 원리에 기반을 둔 것이다. 경험을 회고(hindsight) 하면서 유용한 것을 학습할 수 있는 인간의 능력을 모방한 방법이다.
예를 들어 그림과 같이 골프 홀컵에 공을 넣을 때에만 보상이 주어지고 그렇지 않으면 보상이 없는 게임이 있다고 하자. 만약 홀컵에서 약간 왼쪽으로 빗나간 곳에 골프 공이 떨어졌다고 하면, 강화학습에서는 이 경우 전혀 보상을 받지 못하기 때문에 학습이 되지 않는다. 하지만 사람의 경우에는 이러한 실패한 시도에서도 '다음에는 약간 공을 오른쪽으로 치면 되지 않을까' 하는 유용한 학습 경험을 가질 수 있다.

이 방법을 강화학습에 어떻게 도입할 수 있을까. HER의 아이디어는 골프 홀컵을 원래 위치에서 공이 떨어진 위치로 잠시 이동시키는 것이다. 원래 목표가 실제 골프 홀컵이 있는 위치가 아니라 공이 떨어진 위치였다고 상상하며 이러한 상상속에서 에이전트가 목표에 성공적으로 도달했고 그렇게 함으로써 긍정적인 보상을 받았다고 생각하는 것이다.

논문에 있는 Bit-Flipping (비트 뒤집기) 실험을 Tensorflow2로 구현해 보면서 구체적으로 HER 알고리즘을 살펴보기로 한다.
이 실험에서는 이진수 (0, 1)로 구성된 초기 이진 상태(state) 벡터와 이진 목표(goal) 벡터가 주어지고, 에이전트는 각 시간 단계에서 매번 상태를 구성하는 비트 하나를 0에서 1로 또는 1에서 0으로 바꿀 수 있다. 이런 식으로 초기 상태에서 목표 상태로 이동해 나간다. 에피소드는 상태벡터가 목표벡터와 일치하거나 또는 정해진 횟수를 초과하면 종료된다. 이 때 목표에 도달하면 에이전트는 보상 0을 받고, 그렇지 못하면 보상 -1을 받는다. 따라서 이 문제는 에이전트가 목표에 도달했을 때 비로서 음수가 아닌 보상을 받는 환경이므로 희소 바이너리 보상 문제가 된다.
얘를 들어서 길이가 5인 이진 상태벡터와 목표벡터가 있다면,

에이전트의 행동은 매 시간스텝마다 상태벡터의 특정 위치 비트를 뒤집는 것이다.

무작위로 비트를 뒤집다가 우연히 목표벡터와 일치할 가능성은 매우 희박하므로 학습방법으로 DQN을 도입한다. HER는 오프-폴리시(off-policy)라면 어떤 방법이든 사용 가능하다.
다음 코드는 비트수가 \(n\) 개인 Bit-Flipping 클래스이다.
class BitFlipping:
def __init__(self, n):
self.n = n # number of bits
def reset(self):
self.goal = np.random.randint(2, size=(self.n))
self.state = np.random.randint(2, size=(self.n))
return np.copy(self.state), np.copy(self.goal)
def step(self, action):
self.state[action] = 1-self.state[action] # flip this bit
done = np.array_equal(self.state, self.goal)
if done:
reward = 0
else:
reward = -1
return np.copy(self.state), reward, done
def render(self):
print("\rstate :", np.array_str(self.state), end=' '*10)
HER에서는 에피소드 마다 가상의 목표가 달라지므로 되므로 버퍼에 목표도 함께 저장해야 한다. 따라서 다음과 같이 기존 리플레이 버퍼(replay buffer)를 수정하여 천이샘플(transition sample) 뿐만 아니라 목표 \(\mathbf{g}\) 도 저장하도록 만든다.
\[ (\mathbf{x}_0, \mathbf{a}_0, r_0, \mathbf{x}_1, \mathbf{g}), \ \ (\mathbf{x}_1, \mathbf{a}_1, r_1, \mathbf{x}_2, \mathbf{g}), \ ... \ , \ \ (\mathbf{x}_n, \mathbf{a}_n, r_n, \mathbf{x}_{n+1}, \mathbf{g} ) \]
def add_buffer(self, state, action, reward, next_state, done, goal):
transition = (state, action, reward, next_state, done, goal)
HER를 사용하는 DQN은 상태 뿐만 아니라 목표도 입력으로 받아야 한다. 그래야 에피소드 마다 달라지는 목표를 반영할 수 있다. 상태와 목표는 결합(concatenate)하여 한개의 벡터로 신경망에 입력으로 준다. 출력은 각각의 행동에 대한 \(Q\) 값이다.

state = np.reshape(state, (1, -1))
goal = np.reshape(goal, (1, -1))
state_goal = np.concatenate([state, goal], axis=1)
qs = self.dqn(tf.convert_to_tensor(state_goal))
한개의 에피소드가 끝나면 가상의 목표를 설정하고 리플레이 버퍼에 저장된 천이샘플과 본래 목표를 끄집어 내서 본래 목표를 가상의 목표로 바꾸고 보상을 재설정한 후, HER 버퍼에 저장한다.
\[ \begin{align} & (\mathbf{x}_0, \mathbf{a}_0, r_0, \mathbf{x}_1, \mathbf{g}), \ \ (\mathbf{x}_1, \mathbf{a}_1, r_1, \mathbf{x}_2, \mathbf{g}), \ ... \ , \ \ (\mathbf{x}_n, \mathbf{a}_n, r_n, \mathbf{x}_{n+1}, \mathbf{g} ) \\ \\ \to & \ (\mathbf{x}_0, \mathbf{a}_0, r'_0, \mathbf{x}_1, \mathbf{g}'), \ \ (\mathbf{x}_1, \mathbf{a}_1, r'_1, \mathbf{x}_2, \mathbf{g}'), \ ... \ , \ \ (\mathbf{x}_n, \mathbf{a}_n, r'_n, \mathbf{x}_{n+1}, \mathbf{g}' ) \end{align} \]
여기서 리플레이 버퍼는 원래 목표 하에 실행된 샘플을 저장하는 버퍼와 가상의 목표로 재 설정된 샘플을 저장하는 HER 버퍼 등 2개다.
self.experience = her_buffer(self.BUFFER_SIZE)
self.her_experience = her_buffer(self.BUFFER_SIZE)
논문에는 가상의 목표를 설정하는 방법으로 4가지가 제시되어 있다. 그 중 첫번째는 'final' 으로서 에피소드 종료 싯점의 상태값을 가상의 목표로 정하는 방법이다. 두번째는 'future' 로서 에피소드에서 k개의 임의의 시간스텝을 선택한 후 그 다음 스텝의 상태를 가상의 목표로 정하는 방법이다. 한 개의 에피소드에서 k개의 목표가 새로이 생기므로 도달 가능한 목표 집합을 대폭 늘린 것이다. 논문에 의하면 'future' 와 'final' 의 성능이 다른 방법보다 특히 좋았다고 한다. 다음 코드는 이 두 개의 방법을 구현한 것이다.
for t in range(self.experience.buffer_count()):
if her_method == 'future': # K-future HER
for k in range(4): # number of future states
future = np.random.randint(t, self.experience.buffer_count())
# pretend the goal was to reach the next state of future
fake_goal = self.experience.buffer[future][3] # next_state of future
state = self.experience.buffer[t][0]
action = self.experience.buffer[t][1]
next_state = self.experience.buffer[t][3]
# if the next state is equal to this fake goal, the reward is 0, else -1
done = np.array_equal(next_state, fake_goal)
fake_reward = 0 if done else -1
# add this new experience to the hindsight memory
self.her_experience.add_buffer(state, action, fake_reward, next_state, done, fake_goal)
elif her_method == 'final': # final
# pretend the goal was to reach the final state
fake_goal = self.experience.buffer[-1][0] # state
state = self.experience.buffer[t][0]
action = self.experience.buffer[t][1]
next_state = self.experience.buffer[t][3]
# if the state is equal to this fake goal, the reward is 0, else -1
done = np.array_equal(state, fake_goal)
fake_reward = 0 if done else -1
# add this new experience to the hindsight replay buffer
self.her_experience.add_buffer(state, action, fake_reward, next_state, done, fake_goal)
이와 같이 리플레이 버퍼에 가상의 목표에 따른 가상의 궤적을 도입함으로써 정책이 나쁘더라도 항상 긍정적인 보상을 얻을 수 있다.
여기서 과연 원래 목표와 상관 없는 가상의 목표를 달성하기 위해 하는 학습이 무슨 소용이 있는지 의아해 할 수 있다. 중요한 것은 신경망의 입력으로 상태 뿐만 아니라 가상의 목표도 함께 준다는 데 있다. 신경망은 주어진 목표가 가상이든 실제이든 목표에 도달하는 정책을 학습할 것이고 이것이 에이전트가 더 잘 탐색하고 실제 원하는 목표에 도달하는 중간 목표를 배우는 데 도움이 된다는 것이다. 이를 통해 에이전트는 실제로 주어진 목표 상태에 도달하는 방법을 학습하게 된다.
HER 버퍼가 일정량 들어차면 버퍼에서 N개의 샘플을 무작위로 추출하여 DQN 알고리즘에 의한 학습을 진행한다. 여기서는 Double DQN 알고리즘 (https://pasus.tistory.com/135)을 사용했다.
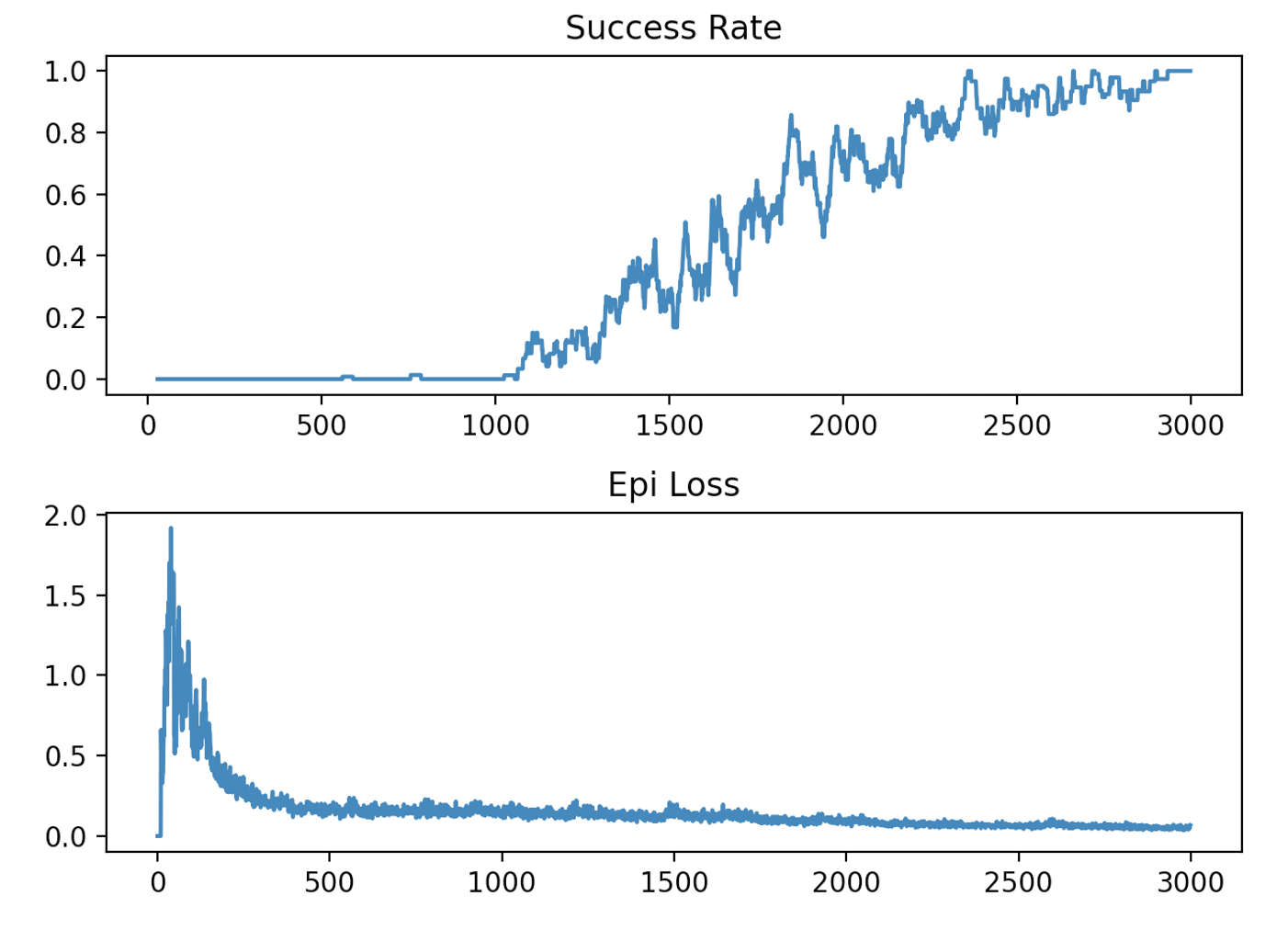
비트수가 15개인 Bit-Flipping 환경을 대상으로 'final' 을 사용했을 때의 학습 결과는 다음과 같다. 약 3000 에피소드후에 에이전트는 목표 달성 성공율이 거의 100%에 육박한 것을 알 수 있다.
학습 후 5번의 평가 테스트 결과는 다음과 같다. 모두 목표에 도달했음을 알 수 있다.

이번에는 동일한 환경을 대상으로 'future' 를 사용했을 때의 학습 결과다. \(k=4\) 를 사용했다. 'final' 보다 빠른 약 2000 에피소드후에 거의 100%의 성공율을 보인 것을 알 수 있다.

학습 후 5번의 평가 테스트 결과는 다음과 같다. 모두 목표에 도달했음을 알 수 있다.

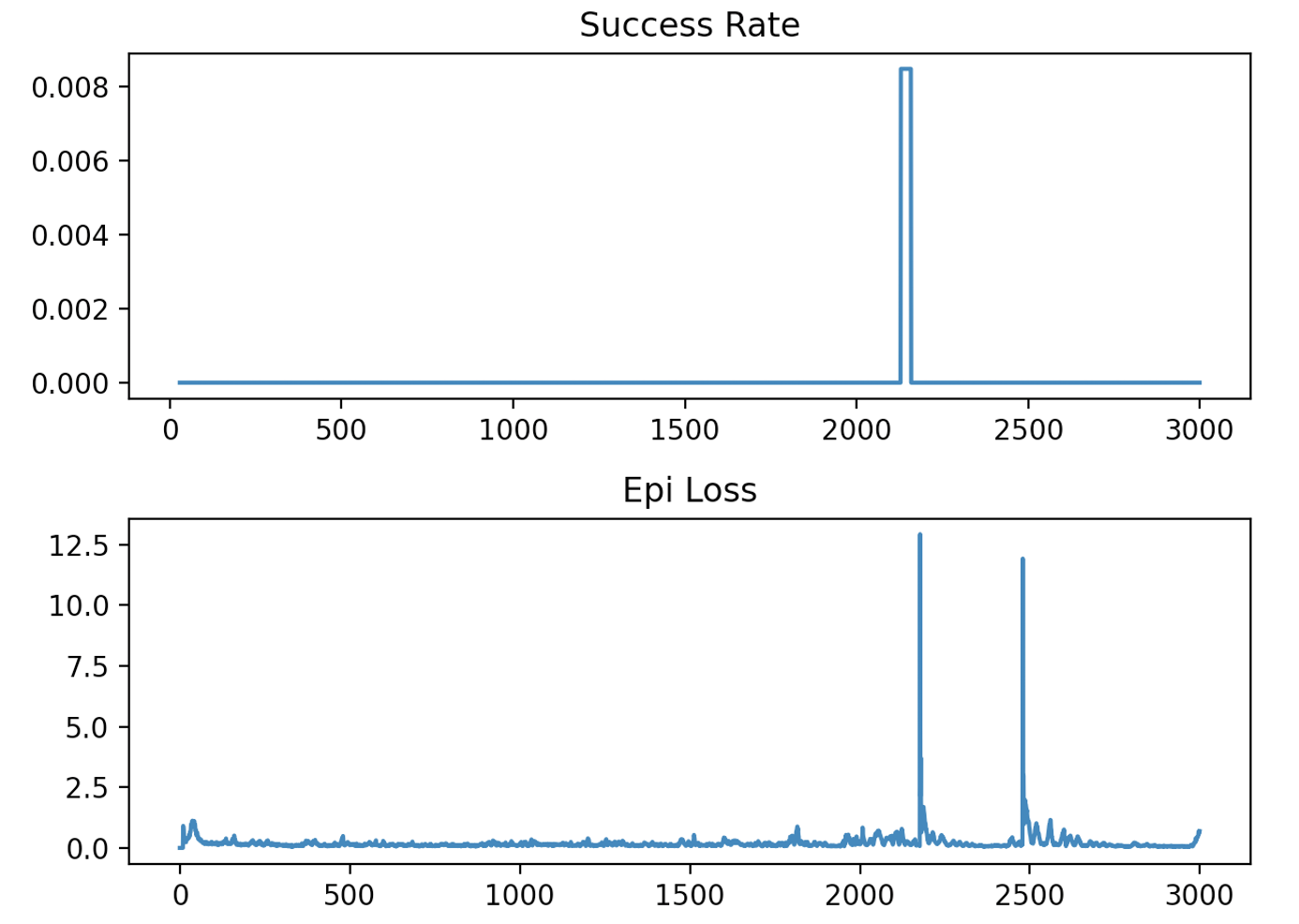
다음은 HER 버퍼를 사용하지 않고 일반 리플레이 버퍼에 있는 데이터를 사용했을 때의 학습 결과다. 전혀 학습이 이루어지지 않은 것을 알 수 있다.
다음은 전체 코드이다.
her_buffer.py
# Hindsight Replay Buffer
# coded by St.Watermelon
import numpy as np
from collections import deque
import random
class HERBuffer:
"""
Hindsight Reply Buffer
"""
def __init__(self, buffer_size):
self.buffer_size = buffer_size
self.buffer = deque()
self.count = 0
## save to buffer
def add_buffer(self, state, action, reward, next_state, done, goal):
transition = (state, action, reward, next_state, done, goal)
# check if buffer is full
if self.count < self.buffer_size:
self.buffer.append(transition)
self.count += 1
else:
self.buffer.popleft()
self.buffer.append(transition)
## sample a batch
def sample_batch(self, batch_size):
if self.count < batch_size:
batch = random.sample(self.buffer, self.count)
else:
batch = random.sample(self.buffer, batch_size)
# return a batch of transitions
states = np.asarray([i[0] for i in batch])
actions = np.asarray([i[1] for i in batch])
rewards = np.asarray([i[2] for i in batch])
next_states = np.asarray([i[3] for i in batch])
dones = np.asarray([i[4] for i in batch])
goals = np.asarray([i[5] for i in batch])
return states, actions, rewards, next_states, dones, goals
## Current buffer occupation
def buffer_count(self):
return self.count
## Clear buffer
def clear_buffer(self):
self.buffer = deque()
self.count = 0
her_flip_learn.py
# HER bit-flipping DQN
# coded by St.Watermelon
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
from her_buffer import HERBuffer as her_buffer
class BitFlipping:
def __init__(self, n):
self.n = n # number of bits
def reset(self):
self.goal = np.random.randint(2, size=(self.n))
self.state = np.random.randint(2, size=(self.n))
return np.copy(self.state), np.copy(self.goal)
def step(self, action):
self.state[action] = 1-self.state[action] # flip this bit
done = np.array_equal(self.state, self.goal)
if done:
reward = 0
else:
reward = -1
return np.copy(self.state), reward, done
def render(self):
print("\rstate :", np.array_str(self.state), end=' '*10)
# DQN network
class DQN(Model):
def __init__(self, action_n):
super(DQN, self).__init__()
self.h1 = Dense(256, activation='relu')
self.q = Dense(action_n, activation='linear')
def call(self, x):
x = self.h1(x)
q = self.q(x)
return q
class DQNagent:
def __init__(self, env, state_dim, action_n, goal_dim):
## hyperparameters
self.GAMMA = 0.99
self.BATCH_SIZE = 256
self.BUFFER_SIZE = int(1e6)
self.DQN_LEARNING_RATE = 0.005
self.TAU = 0.05
self.EPSILON = 0.2
self.EPSILON_DECAY = 0.95
self.EPSILON_MIN = 0.02
self.env = env
# get state dimension and action number
self.state_dim = state_dim
self.action_n = action_n
self.goal_dim = goal_dim
## create Q networks
self.dqn = DQN(self.action_n)
self.target_dqn = DQN(self.action_n)
self.dqn.build(input_shape=(None, self.state_dim+self.goal_dim))
self.target_dqn.build(input_shape=(None, self.state_dim+self.goal_dim))
self.dqn.summary()
# optimizer
self.dqn_opt = Adam(self.DQN_LEARNING_RATE)
## initialize replay buffer
self.experience = her_buffer(self.BUFFER_SIZE)
self.her_experience = her_buffer(self.BUFFER_SIZE)
# save the results
self.save_epi_loss = []
self.success_rate = []
## get action
def choose_action(self, state, goal):
if np.random.random() <= self.EPSILON:
return np.random.randint(self.action_n)
else:
state = np.reshape(state, (1, -1))
goal = np.reshape(goal, (1, -1))
state_goal = np.concatenate([state, goal], axis=1)
qs = self.dqn(tf.convert_to_tensor(state_goal))
return np.argmax(qs.numpy())
## transfer actor weights to target actor with a tau
def update_target_network(self, TAU):
phi = self.dqn.get_weights()
target_phi = self.target_dqn.get_weights()
for i in range(len(phi)):
target_phi[i] = TAU * phi[i] + (1 - TAU) * target_phi[i]
target_phi = phi
self.target_dqn.set_weights(target_phi)
## single gradient update on a single batch data
def dqn_learn(self, state_goals, actions, td_targets):
with tf.GradientTape() as tape:
one_hot_actions = tf.one_hot(actions, self.action_n)
q = self.dqn(state_goals, training=True)
q_values = tf.reduce_sum(one_hot_actions * q, axis=1, keepdims=True)
loss = tf.keras.losses.MSE(td_targets, q_values)
grads = tape.gradient(loss, self.dqn.trainable_variables)
self.dqn_opt.apply_gradients(zip(grads, self.dqn.trainable_variables))
return tf.reduce_mean(loss).numpy()
## computing TD target: y_k = r_k + gamma* max Q(s_k+1, a)
def td_target(self, rewards, target_qs, dones):
max_q = np.max(target_qs, axis=1, keepdims=True)
y_k = np.zeros(max_q.shape)
for i in range(max_q.shape[0]): # number of batch
if dones[i]:
y_k[i] = rewards[i]
else:
y_k[i] = rewards[i] + self.GAMMA * max_q[i]
return y_k
## load actor weights
def load_weights(self, path):
self.dqn.load_weights(path + 'flip_dqn.h5')
## train the agent
def train(self, max_episode_num, max_episode_len, her_method='final'):
# initial transfer model weights to target model network
self.update_target_network(1.0)
for ep in range(int(max_episode_num)):
# reset episode
ep_length, episode_loss, successes, done = 0, 0, 0, False
# reset the environment and observe the first state and goal
state, goal = self.env.reset()
while not done:
ep_length += 1
# pick an action
action = self.choose_action(state, goal)
# observe reward, new_state
next_state, reward, done = self.env.step(action)
self.experience.add_buffer(state, action, reward, next_state, done, goal)
state = next_state
successes += done
if done or (ep_length >= max_episode_len):
break
# HER
for t in range(self.experience.buffer_count()):
if her_method == 'future': # K-future HER
for k in range(4): # number of future states
future = np.random.randint(t, self.experience.buffer_count())
# pretend the goal was to reach the next state of future
fake_goal = self.experience.buffer[future][3] # next_state of future
state = self.experience.buffer[t][0]
action = self.experience.buffer[t][1]
next_state = self.experience.buffer[t][3]
# if the next state is equal to this fake goal, the reward is 0, else -1
done = np.array_equal(next_state, fake_goal)
fake_reward = 0 if done else -1
# add this new experience to the hindsight memory
self.her_experience.add_buffer(state, action, fake_reward, next_state, done, fake_goal)
elif her_method == 'final': # final
# pretend the goal was to reach the final state
fake_goal = self.experience.buffer[-1][0] # state
state = self.experience.buffer[t][0]
action = self.experience.buffer[t][1]
next_state = self.experience.buffer[t][3]
# if the state is equal to this fake goal, the reward is 0, else -1
done = np.array_equal(state, fake_goal)
fake_reward = 0 if done else -1
# add this new experience to the hindsight replay buffer
self.her_experience.add_buffer(state, action, fake_reward, next_state, done, fake_goal)
elif her_method == 'noher': # no HER
state = self.experience.buffer[t][0]
action = self.experience.buffer[t][1]
reward = self.experience.buffer[t][2]
next_state = self.experience.buffer[t][3]
done = self.experience.buffer[t][4]
goal = self.experience.buffer[t][5]
self.her_experience.add_buffer(state, action, reward, next_state, done, goal)
# clear the normal experience
self.experience.clear_buffer()
# start train after her_buffer has some amounts
if self.her_experience.buffer_count() > 1000:
# decaying EPSILON
if self.EPSILON > self.EPSILON_MIN:
self.EPSILON *= self.EPSILON_DECAY
# sample transitions from her buffer
states, actions, rewards, next_states, dones, goals \
= self.her_experience.sample_batch(self.BATCH_SIZE)
# predict target Q-values
next_state_goals = np.concatenate([next_states, goals], axis=1)
target_qs = self.target_dqn(tf.convert_to_tensor(next_state_goals))
# compute TD targets
y_i = self.td_target(rewards, target_qs.numpy(), dones)
# train critic using sampled batch
state_goals = np.concatenate([states, goals], axis=1)
loss = self.dqn_learn(tf.convert_to_tensor(state_goals),
actions,
tf.convert_to_tensor(y_i))
# update target network
self.update_target_network(self.TAU)
episode_loss += loss
succ_rate = successes/ep_length * self.action_n
if succ_rate >= 1:
succ_rate = 1
## display rewards every episode
print('Episode: ', ep+1, 'Episode length: ', ep_length, 'Episode loss: ', episode_loss, 'Success rate: ', succ_rate)
self.save_epi_loss.append(episode_loss)
self.success_rate.append(succ_rate)
## save weights every 100 episodes
if (ep+1) % 100 == 0:
self.dqn.save_weights("./save_weights/flip_dqn.h5")
## save them to file if done
def plot_result(self):
fig, axs = plt.subplots(2) # Create 2 subplots
success_rate_series = pd.Series(self.success_rate)
moving_avg_success_rate = success_rate_series.rolling(window=30).mean()
axs[0].plot(moving_avg_success_rate)
axs[0].set_title('Success Rate')
axs[1].plot(self.save_epi_loss)
axs[1].set_title('Epi Loss')
plt.tight_layout() # To ensure no overlapping of plots
plt.show()
if __name__ == "__main__":
size = 15
env = BitFlipping(size)
agent = DQNagent(env, size, size, size)
max_episode_num = 3000
max_episode_len = 100
agent.train(max_episode_num, max_episode_len,'final')
agent.plot_result()
her_flip_eval.py
# HER bit-flipping DQN evaluation
# coded by St.Watermelon
import time
import numpy as np
from her_flip_learn import BitFlipping, DQNagent
def main():
size = 15
env = BitFlipping(size)
agent = DQNagent(env, size, size, size)
agent.load_weights('./save_weights/')
for _ in range(5):
state, goal = env.reset()
print("goal :", np.array_str(goal))
for t in range(size):
action = agent.choose_action(state, goal)
next_state, reward, done = env.step(action)
state = next_state
env.render()
time.sleep(0.5)
if done:
break
print("Success :", done)
if __name__=="__main__":
main()
'AI 딥러닝 > RL' 카테고리의 다른 글
| Tensorflow2로 만든 DDPG 코드: BipedalWalker-v3 (0) | 2021.07.09 |
|---|---|
| 가치 이터레이션 (Value Iteration)과 LQR (0) | 2021.06.23 |
| 정책 이터레이션 (Policy Iteration)과 LQR (0) | 2021.06.22 |
| Tensorflow2로 만든 SAC 코드: Pendulum-v0 (0) | 2021.06.01 |
| Soft Actor Critic (SAC) 알고리즘 - 2 (0) | 2021.05.30 |




댓글