Ho-Kalman 식별 알고리즘에서는 임펄스 반응(impulse response)을 이용하여 마코프 파라미터(Markov parameters)를 측정하였다. 그렇다면 일반적인 입출력 데이터를 이용하여 마코프 파라미터를 획득하는 방법은 없을까.
다음과 같이 미지의 이산시간(discrete-time) 선형 시스템이 있다고 하자.
\[ \begin{align} & \mathbf{x}_{k+1}=A \mathbf{x}_k+B \mathbf{u}_k \tag{1} \\ \\ & \mathbf{y}_k=C \mathbf{x}_k+D \mathbf{u}_k \end{align} \]
여기서 \(\mathbf{x}_k \in \mathbb{R}^n\), \(\mathbf{u}_k \in \mathbb{R}^p\), \(\mathbf{y}_k \in \mathbb{R}^q\), \( A \in \mathbb{R}^{n \times n}\), \(B \in \mathbb{R}^{n \times p}\), \(C \in \mathbb{R}^{q \times n}\), \(D \in \mathbb{R}^{q \times p}\) 이다.
시간스텝 \(k\) 에서 출력은 다음과 같이 계산할 수 있다.
\[ \begin{align} \mathbf{y}_0 &= C \mathbf{x}_0+D \mathbf{u}_0 \tag{2} \\ \\ \mathbf{y}_1 &= C \mathbf{x}_1+D \mathbf{u}_1 \\ &=C(A \mathbf{x}_0+B \mathbf{u}_0 )+D \mathbf{u}_1 \\ &=CA \mathbf{x}_0+CB \mathbf{u}_0+D \mathbf{u}_1 \\ \\ \mathbf{y}_2 &= C\mathbf{x}_2+D \mathbf{u}_2 \\ &=C(A \mathbf{x}_1+B \mathbf{u}_1 )+D \mathbf{u}_2 \\ &=CA^2 \mathbf{x}_0+CAB \mathbf{u}_0+CB \mathbf{u}_1+D \mathbf{u}_2 \\ \\ & \cdots \\ \\ \mathbf{y}_k &=CA^k \mathbf{x}_0+ \sum_{i=0}^{k-1} CA^{k-1-i} B \mathbf{u}_i +D \mathbf{u}_k \end{align} \]
초기값이 \(0\) 이라고 가정하면, 즉 \(\mathbf{x}_0=0\) 이면 시간스텝 \(k\) 에서 출력은 다음과 같이 된다.
\[ \mathbf{y}_k = \sum_{i=0}^{k-1} CA^{k-1-i} B \mathbf{u}_i +D \mathbf{u}_k \tag{3} \]
식 (3)을 \(k=0, 1, ..., l-1\) 에서 행렬 형식으로 쓰면 다음과 같다.
\[ \mathbf{y}_{0:l-1}=YU \tag{4} \]
여기서
\[ \begin{align} & \mathbf{y}_{0:l-1}=[\mathbf{y}_0 \ \ \mathbf{y}_1 \ \ \mathbf{y}_2 \ \ \cdots \ \ \mathbf{y}_{l-1} ] \ \in \mathbb{R}^{q \times l} \tag{5} \\ \\ & Y=[D \ \ CB \ \ CAB \ \ \cdots \ \ CA^{l-2} B] \ \in \mathbb{R}^{q \times pl} \\ \\ & U= \begin{bmatrix} \mathbf{u}_0 & \mathbf{u}_1 & \mathbf{u}_2 & \cdots & \mathbf{u}_{l-1} \\ & \mathbf{u}_0 & \mathbf{u}_1 & \cdots & \mathbf{u}_{l-2} \\ & & \mathbf{u}_0 & \cdots & \mathbf{u}_{l-3} \\ & & & \ddots & \vdots \\ & & & & \mathbf{u}_0 \end{bmatrix} \ \in \mathbb{R}^{pl \times l} \end{align} \]
이다. \(U\) 와 \(\mathbf{y}_{0:l-1}\) 는 입출력 데이터로만 이루어진 행렬이고 마코프 파라미터로 구성된 행렬 \(Y\) 는 추정할 대상이다.
식 (5)에 의하면 총 식의 개수는 \(q \times l\) 이고 추정해야 할 미지수 개수는 \(q \times pl\) 이다. 따라서 미지수의 개수가 식의 개수보다 많기 때문에 \(p=1\) 즉 입력이 \(1\) 개일 때를 제외하고는 \(Y\) 는 무수히 많은 해가 존재하며 유일하게 계산해 낼 수 없다. 입력이 1개 이더라도 \(Y= \mathbf{y}_{0:l-1} U^{-1}\) 이어야 하므로 \(U^{-1}\) 가 존재해야 하기 때문에 \(\mathbf{u}_0 \ne 0\) 이어야 하고 입력이 충분히 복잡해야 한다.
하지만 만약 행렬 \(A\) 가 안정(stable)하여서 어떤 시간스텝 \(k \ge l_0\) 에서는 \(A^k \approx 0\) 이 된다면 \(k \ge l_0\) 구간에서는 식 (3)을 다음과 같이 근사화할 수 있다.
\[ \begin{align} \mathbf{y}_k &= \sum_{i=0}^{k-1} CA^{k-1-i} B \mathbf{u}_i +D \mathbf{u}_k \tag{6} \\ \\ &= \sum_{i=0}^{k-l_0-1} CA^{k-1-i} B \mathbf{u}_i + \sum_{i=k-l_0}^{k-1} CA^{k-1-i} B \mathbf{u}_i +D \mathbf{u}_k \\ \\ & \approx \sum_{i=k-l_0}^{k-1} CA^{k-1-i} B \mathbf{u}_i +D \mathbf{u}_k, \ \ \ k \ge l_0 \end{align} \]
식 (6)에 의하면 식 (4)와 (5)는 다음과 같이 근사화 된다.
\[ \mathbf{y}_{0:l-1} \approx YU \tag{7} \]
여기서
\[ \begin{align} & \mathbf{y}_{0:l-1}=[\mathbf{y}_0 \ \ \mathbf{y}_1 \ \ \mathbf{y}_2 \ \ \cdots \ \ \mathbf{y}_{l_0} \ \ \cdots \ \ \mathbf{y}_{l-1} ] \ \in \mathbb{R}^{q \times l} \tag{8} \\ \\ & Y=[D \ \ CB \ \ CAB \ \ \cdots \ \ CA^{l_0-1} B] \ \in \mathbb{R}^{q \times p(l_0+1)} \\ \\ & U= \begin{bmatrix} \mathbf{u}_0 & \mathbf{u}_1 & \mathbf{u}_2 & \cdots & \mathbf{u}_{l_0} & \cdots & \mathbf{u}_{l-1} \\ & \mathbf{u}_0 & \mathbf{u}_1 & \cdots & \mathbf{u}_{l_0-1} & \cdots & \mathbf{u}_{l-2} \\ & & \mathbf{u}_0 & \cdots & \mathbf{u}_{l_0-2} & \cdots & \mathbf{u}_{l-3} \\ & & & \ddots & \vdots & \cdots & \vdots \\ & & & & \mathbf{u}_0 & \cdots & \mathbf{u}_{l-l_0-1} \end{bmatrix} \ \in \mathbb{R}^{p(l_0+1) \times l} \end{align} \]
이다. 식 (8)에 의하면 총 식의 개수는 \(q \times l\) 이고 추정해야 할 미지수 개수는 \(q \times p(l_0+1)\) 이다. 따라서 식 (8)에서 데이터의 길이 \(l\) 을 \(p(l_0+1)\) 이상으로 잡으면, 즉 \(l \ge p(l_0+1)\) 이면 식의 개수가 미지수의 개수보다 커지므로 행렬 \(Y\) 를 다음과 같이 근사적으로 계산할 수 있다.
\[ Y= \mathbf{y}_{0:l-1} U^+ \tag{9} \]
여기서 \(U^+\) 는 \(U\) 의 유사 역행렬(pseudo inverse matrix)이다. 행렬 \(U\) 는 입력 데이터 \(\mathbf{u}_i\) 로 구성되어 있으므로 \(\mathbf{u}_i\) 는 \(U\) 의 유사 역행렬이 존재할 수 있도록 충분히 복잡하게 설계되어야 한다.
식 (9)에서 계산한 마코프 파라미터를 Ho-Kalman 식별 알고리즘에 대입하면 미지의 시스템 (1)의 행렬 \(A, B, C, D\) 와 시스템 차수를 식별(identification)할 수 있다. 이와 같은 식별 방법을 ERA(eigensystem realization algorithm)이라고 한다.
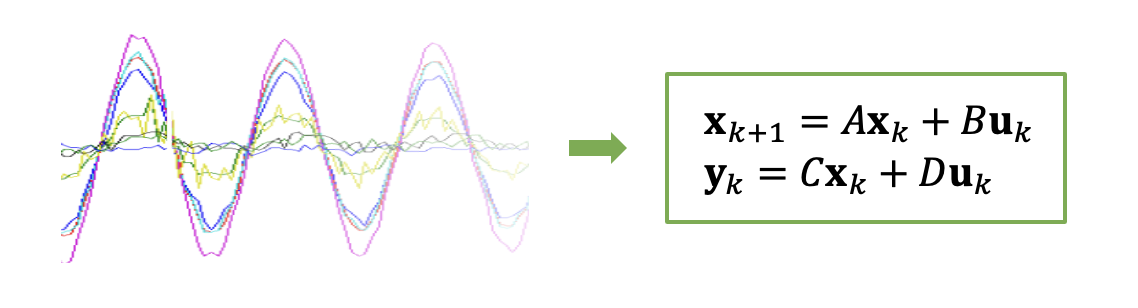
식 (6)에 의하면 근사화에 의한 오차는 \(l_0\) 가 커질 수록 작아질 것이다. 하지만 \(U\) 의 사이즈도 같이 커지기 때문에 유사 역행렬 \(U^+\) 를 계산하는데 어려움이 따른다. 만약 시스템이 덜 안정적일 경우, 즉 감쇄가 느리게 진행될 경우, 정수 \(l_0\) 를 큰 값으로 정해야 하기 때문에 ERA 는 실용성이 떨어진다.
그렇다면 인위적으로 시스템의 안정성을 높일 방법은 없을까. 그리고 초기값이 \(0\) 이어야 한다는 제약을 푸는 방법은 없을까.
'유도항법제어 > 데이터기반제어' 카테고리의 다른 글
| OKID (Observer Kalman Filter Identification) (0) | 2023.03.25 |
|---|---|
| Ho-Kalman 식별 알고리즘 (0) | 2023.03.24 |
| 마코프 파라미터 (Markov Parameters) (0) | 2023.03.22 |
| [DMD-3] DMDior (0) | 2022.11.08 |
| [DMD-2] DMDio (0) | 2022.10.31 |




댓글