소프트 상태가치와 소프트 행동가치의 시간적인 관계식을 알아보기 위해서, 소프트 행동가치 함수를 한 시간스텝 전개해 보자.
\[ \begin{align} & Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \tag{1} \\ \\ & \ \ = \int_{\tau_{x_{t+1}:u_T }} \left( \sum_{k=t}^T \gamma^{k-t} \left( r_k -\gamma \alpha \log \pi (\mathbf{u}_{k+1} | \mathbf{x}_{k+1} ) \right) \right) p(\tau_{x_{t+1}:u_T } | \mathbf{x}_t, \mathbf{u}_t ) d \tau_{x_{t+1}:u_T } \\ \\ & \ \ = \int_{\tau_{x_{t+1}:u_T }} \left( r_t + \sum_{k=t+1}^T \gamma^{k-t} \left( r_k - \alpha \log \pi (\mathbf{u}_k | \mathbf{x}_k ) \right) \right) p(\tau_{x_{t+1}:u_T } | \mathbf{x}_t, \mathbf{u}_t ) d \tau_{x_{t+1}:u_T } \\ \\ & \ \ = r_t + \int_{\tau_{x_{t+1}:u_T }} \left( \sum_{k=t+1}^T \gamma^{k-t} \left( r_k - \alpha \log \pi (\mathbf{u}_k | \mathbf{x}_k ) \right) \right) p(\tau_{x_{t+1}:u_T } | \mathbf{x}_t, \mathbf{u}_t ) d \tau_{x_{t+1}:u_T } \end{align} \]
위 식에서 조건부 확률밀도함수에 확률의 연쇄법칙을 적용하면 다음과 같이 된다.
\[ \begin{align} p(\tau_{x_{t+1}:u_T } | \mathbf{x}_t, \mathbf{u}_t ) &= p(\mathbf{x}_{t+1}, \tau_{u_{t+1}:u_T } | \mathbf{x}_t, \mathbf{u}_t ) \tag{2} \\ \\ &= p(\tau_{u_{t+1}:u_T } | \mathbf{x}_{t+1}, \mathbf{x}_t, \mathbf{u}_t ) \ p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t ) \\ \\ &= p(\tau_{u_{t+1}:u_T } | \mathbf{x}_{t+1}) \ p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t ) \end{align} \]
여기서 \(\tau_{u_{t+1}:u_T } = ( \mathbf{u}_{t+1}, ... , \mathbf{u}_T)\) 이다. 위 식의 마지막 단계는 마르코프(Markov) 시퀀스 가정을 사용한 것이다.
식 (2)를 식 (1)의 적분 식에 적용하면 다음과 같이 된다.
\[ \begin{align} & \int_{\tau_{x_{t+1}:u_T }} \left( \sum_{k=t+1}^T \gamma^{k-t} \left( r_k - \alpha \log \pi (\mathbf{u}_k | \mathbf{x}_k ) \right) \right) p(\tau_{x_{t+1}:u_T } | \mathbf{x}_t, \mathbf{u}_t ) d \tau_{x_{t+1}:u_T } \tag{3} \\ \\ & \ = \int_{\tau_{x_{t+1}:u_T }} \left( \sum_{k=t+1}^T \gamma^{k-t} \left( r_k - \alpha \log \pi (\mathbf{u}_k | \mathbf{x}_k ) \right) \right) p(\tau_{u_{t+1}:u_T } | \mathbf{x}_{t+1}) \ p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t ) d \tau_{x_{t+1}:u_T } \\ \\ & \ = \int_{\mathbf{x}_{t+1}} \gamma \left[ \int_{\tau_{u_{t+1}:u_T }} \left( \sum_{k=t+1}^T \gamma^{k-t-1} \left( r_k -\alpha \log \pi (\mathbf{u}_k | \mathbf{x}_k ) \right) \right) p(\tau_{u_{t+1}:u_T } | \mathbf{x}_{t+1}) \ d \tau_{u_{t+1}:u_T } \right] p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t ) d \mathbf{x}_{t+1} \end{align} \]
소프트 상태가치 함수의 정의에 의하면 위 식은 대괄호항은 \(V_{soft}^\pi (\mathbf{x}_{t+1} )\) 이다. 따라서 소프트 행동가치 함수는 다음과 같이 된다.
\[ \begin{align} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t) &= r_t + \gamma \int_{\mathbf{x}_{t+1}} V^\pi_{soft} (\mathbf{x}_{t+1}) p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t ) d \mathbf{x}_{t+1} \tag{4} \\ \\ &= r_t + \gamma \mathbb{E}_{\mathbf{x}_{t+1} \sim p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t )} \left[ V^\pi_{soft} (\mathbf{x}_{t+1}) \right] \end{align} \]
소프트 상태가치 함수와 행동가치 함수의 관계식은 아래 식과 같으므로,
\[ V_{soft}^\pi (\mathbf{x}_t ) = \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) - \alpha \log \pi (\mathbf{u}_t | \mathbf{x}_t ) \right] \tag{5} \]
식 (4)를 식 (5)에 대입하면, 소프트 상태가치 함수는 다음과 같이 된다.
\[ V_{soft}^\pi (\mathbf{x}_t ) = \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ r_t + \gamma \mathbb{E}_{\mathbf{x}_{t+1} \sim p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t )} \left[ V^\pi_{soft} (\mathbf{x}_{t+1}) \right] - \alpha \log \pi (\mathbf{u}_t | \mathbf{x}_t ) \right] \tag{6} \]
식 (5)를 식 (4)에 대입하면 소프트 행동가치 함수는 다음과 같이 된다.
\[ \begin{align} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t) & = r_t + \gamma \ \mathbb{E}_{\mathbf{x}_{t+1} \sim p(\mathbf{x}_{t+1} | \mathbf{x}_t, \mathbf{u}_t ), \mathbf{u}_{t+1} \sim \pi (\mathbf{u}_{t+1} | \mathbf{x}_{t+1} ) } \tag{7} \\ \\ & \ \ \ \ \ \left[ Q_{soft}^\pi (\mathbf{x}_{t+1}, \mathbf{u}_{t+1} ) - \alpha \log \pi (\mathbf{u}_{t+1} | \mathbf{x}_{t+1} ) \right] \end{align} \]
식 (6)과 (7)을 각각 소프트 벨만 방정식(soft Bellman equation)이라고 한다.
표준 목적함수 문제에서 탐욕(greedy)적인 방법으로 정책을 계산하였듯이 이제 최대 엔트로피 목적함수 문제에서도 탐욕적인 방법으로 정책을 계산해 보자. 탐욕적인 방법이란 현재의 시간스텝만을 고려하여 최대값을 구하는 것을 의미한다.
현재 시간스텝 \(t\) 에서 \(\mathbf{x}_t\) 가 주어졌을 때 최대 엔트로피 목적함수는 다음과 같다.
\[ \begin{align} J_t &=V_{soft}^\pi (\mathbf{x}_t ) \tag{8} \\ \\ &= \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) - \alpha \log \pi (\mathbf{u}_t | \mathbf{x}_t ) \right] \\ \\ &= \int_{\mathbf{u}_t} \left[ Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t)- \alpha \log \pi (\mathbf{u}_t | \mathbf{x}_t ) \right] \pi (\mathbf{u}_t | \mathbf{x}_t) d\mathbf{u}_t \end{align} \]
식 (8)은 소프트 행동가치가 작다면 정책의 무작위성이 커지면서 탐색 성향이 강하지고 반대로 소프트 행동가치가 크다면 현재의 정책으로 생성된 행동의 가치가 크다는 의미이므로 탐색 대신에 정책의 활용 성향이 커지게 된다고 해석할 수 있겠다.
정책 \(\pi (\mathbf{u}_t | \mathbf{x}_t)\) 에 대한 목적함수의 최대값을 구하기 위하여 다음과 같이 미분 식을 계산한다.
\[ \frac{\partial J_t}{\partial \pi(\mathbf{u}_t | \mathbf{x}_t)} = 0 = \int_{\mathbf{u}_t} \left[ Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t) -\alpha \log \pi (\mathbf{u}_t | \mathbf{x}_t ) - \alpha \right] d\mathbf{u}_t \tag{9} \]
위 식에 의하면 최적 정책은 다음과 같이 주어진다.
\[ \begin{align} \pi (\mathbf{u}_t | \mathbf{x}_t ) & = \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t )-1 \right) \\ \\ & \propto \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) \tag{10} \end{align} \]
최적 정책이 \(\exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) \) 와 비례하는 확률분포를 갖는 것으로 계산되는데 이는 기존 Q-러닝과 DDPG의 탐욕적 정책과는 차이가 있다.

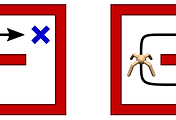
위 그림에서 왼쪽 그림은 기존의 Q-러닝과 DDPG의 접근 방식을 보여준다. 기존 정책은 최대 \(Q\) 값에 중심을 두고 노이즈를 추가하여 인접 \(Q\) 값으로 일정 부분 확장하는 단일 모드 분포를 갖는다.
반면 오른쪽 그림은 식 (10)으로 표현되는 정책의 접근 방식을 보여준다. 정책이 \(Q\) 값의 지수함수에 비례하기 때문에 다중 모드 분포의 형태를 띠며 이에 따라 가능성이 높은 모든 상태를 탐색하고 학습할 수 있게 된다.
표준 목적함수 문제에서는 탐욕적 정책이 확정적 정책이었다면 최대 엔트로피 목적함수 문제에서는 정책이 확률적 정책으로 계산된다. 확률적 정책은 \(\mathbf{u}_t\) 에 관한 조건부 확률밀도함수이므로 면적이 \(1\) 이 되도록 정규화시켜야 한다. 따라서 탐욕적 정책은 다음과 같이 \(\mbox{soft}\max\) 로 주어진다.
\[ \begin{align} \pi (\mathbf{u}_t | \mathbf{x}_t ) & = \frac{ \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) }{ \int_{\mathbf{u}^\prime} \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}^\prime ) \right) d \mathbf{u}^\prime } \tag{11} \\ \\ & = \mbox{soft} \max_{\mathbf{u}_t} \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) \end{align} \]
참고로 표준 목적함수 문제에서는 탐욕적 정책을 \(\arg\max\) 로 계산했다.
\[ \pi (\mathbf{x}_t ) = \arg \max_{\mathbf{u}_t} Q^\pi (\mathbf{x}_t, \mathbf{u}_t ) \tag{11} \]
만약 \(\alpha \to 0\) 이면 식 (11)은 식 (12)와 같아진다.
탐욕적 정책 (11)을 적용한다면 상태가치 함수는 식 (5)에 의해서 다음과 같이 계산된다.
\[ \begin{align} V_{soft}^\pi (\mathbf{x}_t ) &= \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) - \alpha \log \pi (\mathbf{u}_t | \mathbf{x}_t ) \right] \tag{13} \\ \\ &= \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ \alpha \log \int_{\mathbf{u}^\prime} \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}^\prime ) \right) d \mathbf{u}^\prime \right] \\ \\ &=\alpha \log \int_{\mathbf{u}^\prime} \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}^\prime ) \right) d \mathbf{u}^\prime \end{align} \]
한편, 식 (8)의 목적함수를 전개하면 다음과 같이 KL 발산(KL divergence)식과 관련 지울 수 있다.
\[ \begin{align} J_t &= \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) - \alpha \log \pi (\mathbf{u}_t | \mathbf{x}_t ) \right] \tag{14} \\ \\ &= - \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ \alpha \left( \log \pi (\mathbf{u}_t | \mathbf{x}_t ) - \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) \right] \\ \\ &= - \alpha \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ \log \pi (\mathbf{u}_t | \mathbf{x}_t ) - \log \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) \right] \\ \\ &= - \alpha \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ \log \pi (\mathbf{u}_t | \mathbf{x}_t ) - \log \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) + \log Z(\mathbf{x}_t) - \log Z(\mathbf{x}_t) \right] \\ \\ &= - \alpha \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ \log \frac{ \pi (\mathbf{u}_t | \mathbf{x}_t ) }{ \frac{ \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right)}{Z(\mathbf{x}_t)} } - \log Z(\mathbf{x}_t) \right] \\ \\ &= - \alpha D_{KL} \left( \pi (\mathbf{u}_t | \mathbf{x}_t ) \parallel \frac{ \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right)}{Z(\mathbf{x}_t)} \right) + \alpha Z(\mathbf{x}_t) \end{align} \]
여기서 기댓값이 \(\mathbf{u}_t\) 의 조건부 기댓값임을 이용하여 임의의 함수 \(\log Z( \mathbf{x}_t)\) 를 더하고 빼는 트릭을 사용했다. 수식에 있는 \(D_{KL}\) 은 KL 발산 연산자이다.
\(\pi (\mathbf{u}_t | \mathbf{x}_t )\) 가 확률밀도함수이므로 \( \frac{ \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right)}{Z(\mathbf{x}_t)} \) 도 확률밀도함수로 만들기 위해서 \(Z(\mathbf{x}_t )\) 를 도입하였다. \(Z(\mathbf{x}_t )\) 는 정책 확률밀도함수의 면적이 1이 되도록 만드는 정규화 항으로 정하면 된다.
\[ Z(\mathbf{x}_t )= \int_{\mathbf{u}^\prime} \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) d\mathbf{u}^\prime \tag{15} \]
위 수식에 의하면 목적함수 (8)을 최대화하는 정책은 그 정책과 소프트 행동가치 함수의 KL 발산을 최소화하는 정책임을 알 수 있다.
\[ \begin{align} \pi (\mathbf{u}_t | \mathbf{x}_t ) &=\arg\max_\pi \mathbb{E}_{\mathbf{u}_t \sim \pi (\mathbf{u}_t | \mathbf{x}_t ) } \left[ Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) - \alpha \log \pi (\mathbf{u}_t | \mathbf{x}_t ) \right] \tag{16} \\ \\ &= \arg\min_\pi D_{KL} \left( \pi (\mathbf{u}_t | \mathbf{x}_t ) \parallel \frac{ \exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right)}{Z(\mathbf{x}_t)} \right) \end{align} \]
식 (16)을 최소로 만드는 정책은 이미 식 (11)에서 계산했듯이 정책이 \(\exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) \) 와 비례하는 것인데, \(\exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) \) 에 비례하는 확률분포는 핸들링하기가 곤란하다.
따라서 식 (16)은 \(\exp \left( \frac{1}{\alpha} Q_{soft}^\pi (\mathbf{x}_t, \mathbf{u}_t ) \right) \) 에 비례하는 확률분포와 최대한 유사한 가우시안 분포나 균등분포 또는 GMM(Gaussian mixture model)과 같은 확률밀도함수를 계산하기 위한 식으로 이해하는 것이 좋겠다. 가우시안 분포의 경우 수학적으로 다루기도 쉽고 샘플링하기도 쉽다.
'AI 딥러닝 > RL' 카테고리의 다른 글
| Soft Actor Critic (SAC) 알고리즘 - 1 (0) | 2021.05.29 |
|---|---|
| 소프트 정책 이터레이션 (0) | 2021.05.28 |
| 최대 엔트로피 목적함수 (0) | 2021.05.26 |
| Tensorflow2로 만든 DDPG 코드: Pendulum-v0 (0) | 2021.05.14 |
| DQN에서 DDPG로 (0) | 2021.05.14 |



댓글