GP 회귀 (Gaussian process regression) 문제를 정리하면 다음과 같다.
어떤 미지의 함수 \(f(\mathbf{x})\) 를 다음과 같이 가우시안 프로세스로 모델링한다고 하자.
\[ \begin{align} & y=f(\mathbf{x})+\epsilon \tag{1} \\ \\ & \ \ \ \ \ \epsilon \sim \mathcal{N} (0, \sigma_n^2 ) \\ \\ & \ \ \ \ \ f(\mathbf{x}) \sim \mathcal{GP} (\mu(\mathbf{x}), k(\mathbf{x}, \mathbf{x}' )) \end{align} \]
여기서 \(y\) 는 측정값, \(\mathbf{x}\) 는 입력으로서 가우시안 프로세스의 인덱스이고, \(\epsilon\) 는 측정 노이즈, \(f(\mathbf{x})\) 는 평균함수가 \(\mu (\mathbf{x})\), 공분산이 커널함수 \(k(\mathbf{x}, \mathbf{x}' )\) 인 가우시안 프로세스이다. 측정 노이즈는 가우시안 프로세스 \(f(\mathbf{x})\) 와 독립이고 평균이 \(0\), 분산이 \(\sigma_n^2\) 인 가우시안 화이트 노이즈로 가정한다. 가우시안 프로세스의 평균함수와 공분산의 확률 정보는 측정값과 무관하게 설정한 것이므로 사전 확률분포 (GP prior)라고 한다.
이제 \(m\) 개의 데이터셋 \(\mathcal{D} = \{(\mathbf{x}_i, y_i ), \ i=1, ... ,m \}\) 이 주어졌다고 하자. 여기서
\[ \begin{align} & y_i=f_i+\epsilon_i \tag{2} \\ \\ & f_i=f(\mathbf{x}_i) \end{align} \]
이다. 데이터셋을 랜덤벡터 형식으로 표현하면 다음과 같다.
\[ \mathbf{y}_{1:m}= \mathbf{f}_{1:m}+ \epsilon_{1:m} \tag{3} \]
여기서
\[ \mathbf{f}_{1:m}= \begin{bmatrix} f_1 \\ \vdots \\ f_m \end{bmatrix} = \begin{bmatrix} f(\mathbf{x}_1) \\ \vdots \\ f(\mathbf{x}_m) \end{bmatrix} , \ \ \mathbf{y}_{1:m} = \begin{bmatrix} y_1 \\ \vdots \\ y_m \end{bmatrix} , \ \ \epsilon_{1:m}= \begin{bmatrix} \epsilon_1 \\ \vdots \\ \epsilon_m \end{bmatrix} \]
이다.
그러면 랜덤벡터 \(\mathbf{f}_{1:m}\) 의 확률밀도함수(probability density function)는 다음과 같이 주어진다.
\[ \begin{align} & p(\mathbf{f}_{1:m} \vert \mathbf{x}_{1:m} ) = \mathcal{N} (\mathbf{f}_{1:m} \vert \mu_{1:m}, K) \tag{4} \\ \\ & \ \ \ \ \ = \frac{1}{\sqrt{(2 \pi)^m \det K }} \exp \left( -\frac{1}{2} (\mathbf{f}_{1:m}- \mu_{1:m} )^T K^{-1} (\mathbf{f}_{1:m}-\mu_{1:m} ) \right) \end{align} \]
여기서
\[ \mu_{1:m}= \begin{bmatrix} \mu(\mathbf{x}_1) \\ \vdots \\\mu(\mathbf{x}_m) \end{bmatrix}, \ \ K=\begin{bmatrix} K_{11} & \cdots & K_{1m} \\ \vdots & \ddots & \vdots \\ K_{m1} & \cdots & K_{mm} \end{bmatrix} , \ \ K_{ij}=k(\mathbf{x}_i, \mathbf{x}_j) \]
이다.
\(\mathbf{x}_{1:m}\) 는 인덱스로서 랜덤벡터가 아니라 확정적인(deterministic) 값을 갖는 벡터이지만, 표기의 일관성을 유지하기 위하여 마치 랜덤벡터가 특정 값으로 주어진 것처럼 사용했다. 미지의 함수에 대해 사전 정보가 없는 경우 계산 편의상 평균함수 \(\mu(\mathbf{x})=0\) 으로 둔다. 그러면 식 (4)에서 \(\mu_{1:m}=0\) 이다.
한편 \(\mathbf{y}_{1:m}\) 의 조건부 확률밀도함수 \(p(\mathbf{y}_{1:m} \vert \mathbf{f}_{1:m}, \mathbf{x}_{1:m} )\) 는 다음과 같이 주어진다.
\[ \begin{align} p(\mathbf{y}_{1:m} \vert \mathbf{f}_{1:m}, \mathbf{x}_{1:m} ) &= \mathcal{N}( \mathbf{y}_{1:m} \vert \mathbf{f}_{1:m} , \sigma_n^2 I) \tag{5} \\ \\ &= \prod_{i=1}^m \mathcal{N}( y_i \vert f_i, \sigma_n^2 ) \end{align} \]
한계밀도함수(marginal density function)의 정의를 이용하면 랜덤벡터 \(\mathbf{y}_{1:m}\) 의 확률밀도함수를 다음과 같이 계산할 수 있다.
\[ \begin{align} p(\mathbf{y}_{1:m} \vert \mathbf{x}_{1:m} ) & = \int p(\mathbf{y}_{1:m}, \mathbf{f}_{1:m} \vert \mathbf{x}_{1:m} ) \ d \mathbf{f}_{1:m} \tag{6} \\ \\ &= \int p(\mathbf{y}_{1:m} \vert \mathbf{f}_{1:m}, \mathbf{x}_{1:m} ) \ p(\mathbf{f}_{1:m} \vert \mathbf{x}_{1:m} ) \ d \mathbf{f}_{1:m} \end{align} \]
복잡하긴 하지만 식 (4)와 (5)를 이용하면 식 (6)은 다음과 같이 된다.
\[ p(\mathbf{y}_{1:m} \vert \mathbf{x}_{1:m} ) = \mathcal{N}( \mathbf{y}_{1:m} \vert 0, C) \tag{7} \]
여기서 \( C=K+ \sigma_n^2 I\) 이다.
커널함수 형태와 하이퍼파라미터(hyperparameter)는 GP 회귀의 신뢰도에 큰 영향을 미친다. 여러가지 커널함수의 형태가 있지만 가장 많이 사용되는 커널함수는 다음 식으로 주어지는 등방성(isotropic) RBF (radial basis function) 이다.
\[ k(\mathbf{x}, \mathbf{x}') = \sigma_f^2 \exp \left( - \frac{ \lVert \mathbf{x} - \mathbf{x}' \rVert_2^2}{2\lambda^2 } \right) \tag{8} \]
비등방성 (anisotropic) RBF는 입력 벡터 \(\mathbf{x} \in \mathbb{R}^n\) 의 각 성분 간의 너비를 제어할 수 있다.
\[ k(\mathbf{x}, \mathbf{x}') = \sigma_f^2 \exp \left( -\frac{1}{2} (\mathbf{x}-\mathbf{x}' )^T \Lambda^{-1} (\mathbf{x}-\mathbf{x}') \right) \tag{9} \]
여기서 \(\Lambda = diag \{ \lambda_1^2, ... , \lambda_n^2\} \) 이다.
식 (8)과 (9)에 있는 \(\sigma_f^2, \lambda_i^2\) 와 측정 노이즈의 분산 \(\sigma_n^2\) 은 하이퍼파라미터로서 적절하게 선정될 필요가 있다. 하이퍼파라미터에 대한 사전 지식이 전혀 없다고 가정할 때, 데이터셋을 이용하여 확률밀도함수 \(p(\mathbf{y}_{1:m} \vert \mathbf{x}_{1:m} )\) 가 최대가 되도록 만드는 값으로 결정하는 것이 합리적이다. 여기서 \(p(\mathbf{y}_{1:m} \vert \mathbf{x}_{1:m} )\) 는 \(\mathbf{x}_{1:m}\) 를 조건으로 하는 \(\mathbf{y}_{1:m}\) 의 조건부 확률밀도함수로서 \(\mathbf{x}_{1:m}\) 에 따라 특정 측정벡터 \(\mathbf{y}_{1:m}\) 가 얼마나 자주 나타나는가를 나타내는 빈도함수(likelihood function)이다. 하이퍼파라미터를 벡터 형식으로 표현하면,
\[ \Theta = \begin{bmatrix} \sigma_f^2 & \sigma_n^2 & \lambda_1^2 & ... & \lambda_n^2 \end{bmatrix}^T \tag{10} \]
식 (7)의 로그 (log) 형태는 다음과 같다.
\[ \begin{align} & \log p(\mathbf{y}_{1:m} \vert \mathbf{x}_{1:m}, \Theta ) \tag{11} \\ \\ & \ \ \ \ \ = - \frac{1}{2} \mathbf{y}_{1:m}^T C^{-1} \mathbf{y}_{1:m}-\frac{1}{2} \log \det C- \frac{m}{2} \log (2 \pi) \end{align} \]
여기서 \(\Theta\) 도 확정적 벡터이지만 행렬 \(C\) 가 \(\Theta\) 의 함수이므로 \(p(\mathbf{y}_{1:m} \vert \mathbf{x}_{1:m} )\) 도 \(\Theta\) 의 함수임을 명시적으로 표현하고자 학률밀도함수의 조건항에 표기했다.
최적의 하이퍼파라미터는 로그-빈도함수를 최대화하는 값인 최대빈도(ML, maximum likelihood) 추정값으로 정한다.
\[ \Theta^* = \arg \max_{\Theta} \log p(\mathbf{y}_{1:m} \vert \mathbf{x}_{1:m}, \Theta) \tag{12} \]
최대값을 구하는 과정에서 필요한 하이퍼파라미터에 대한 로그-빈도함수의 미분식은 다음과 같다.
\[ \begin{align} & \frac{\partial }{\partial \theta_j } \log p(\mathbf{y}_{1:m} \vert \mathbf{x}_{1:m}, \Theta ) \tag{13} \\ \\ & \ \ \ \ \ = \frac{1}{2} \mathbf{y}_{1:m}^T \frac{\partial C}{\partial \theta_j } C^{-1} \mathbf{y}_{1:m}- \frac{1}{2} tr \left( C^{-1} \frac{\partial C}{\partial \theta_j} \right) \end{align} \]
하이퍼파라미터가 최적화되면 측정 데이터셋 \(\mathcal{D}= \{( \mathbf{x}_i, y_i ), \ i=1, ... ,m \}\) 을 이용하여 임의의 입력 \(\mathbf{x}_*\) 에 대한 출력의 예측값 \( y_*\) 에 대한 사후 확률분포 (GP posterior)를 다음과 같이 계산할 수 있다.
\[ p(y_* \vert \mathbf{x}_* ) = \mathcal{N} (\bar{\mu}, \Sigma) \tag{14} \]
여기서
\[ \begin{align} & \Sigma=k(\mathbf{x}_*, \mathbf{x}_*) - \mathbf{k}^T [ K+ \sigma_n^2 I]^{-1} \mathbf{k} \\ \\ & \bar{\mu} = \mathbf{k}^T [ K+ \sigma_n^2 I]^{-1} \mathbf{y}_{1:m} \\ \\ & \mathbf{k} = \begin{bmatrix} k(\mathbf{x}_1, \mathbf{x}_* ) & ... & k(\mathbf{x}_m, \mathbf{x}_* )\end{bmatrix}^T \end{align} \]
이다.
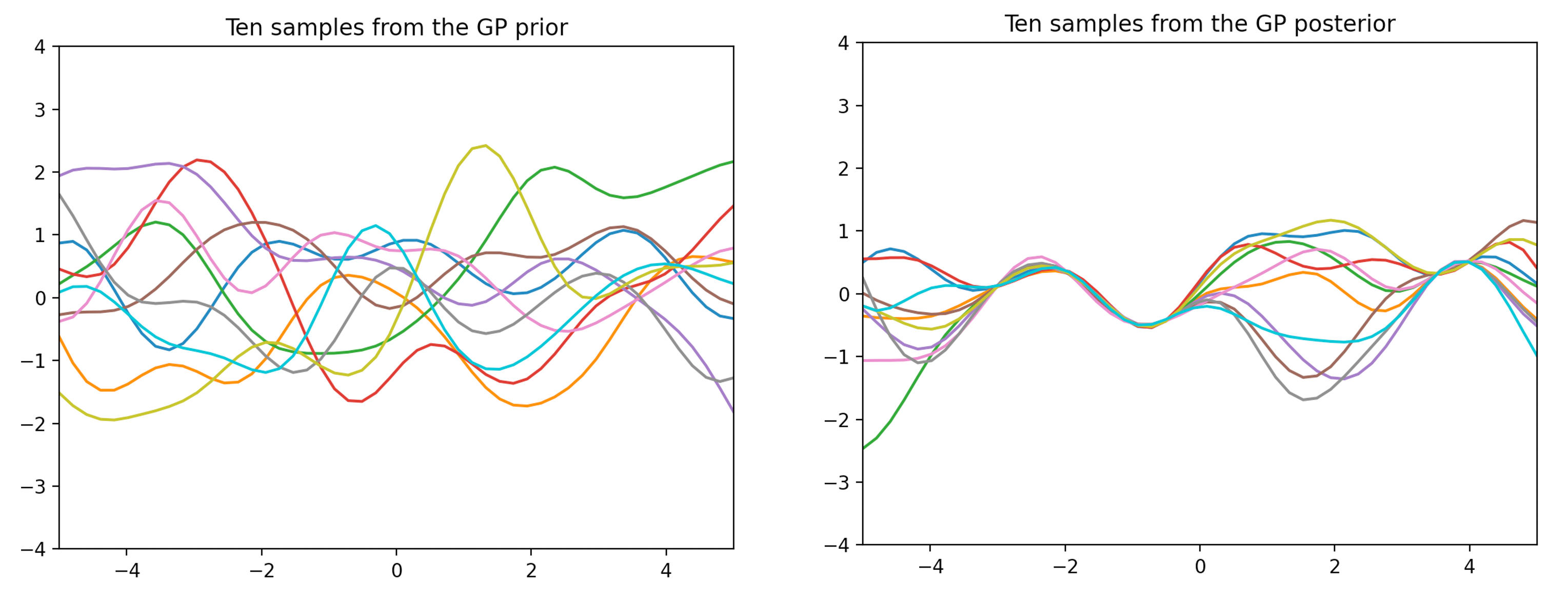
다음 그림은 어떤 가우시안 프로세스의 사전 및 사후 확률분포에서 10개의 샘플함수를 추출하여 그린 것이다. 어떤 미지의 함수를 추정하고자 한 것인지 짐작이 가는가. 데이터가 더 필요하지는 않을까. 필요하다면 어떤 입력에 대한 출력값이 필요할까.
'AI 딥러닝 > ML' 카테고리의 다른 글
| [GP-4] 베이지안 최적화 (Bayesian Optimization) (0) | 2022.07.09 |
|---|---|
| [GP-2] GP 회귀 (GP Regression) (0) | 2022.06.30 |
| [GP-1] 가우시안 프로세스 (Gaussian Process)의 개념 (0) | 2022.06.26 |



댓글