제약조건이 없는 최적화 문제
\[ \min_{\mathbf{x}} f(\mathbf{x}) \tag{1} \]
는 보통 초기 추측값 \(\mathbf{x}^{(0)}\) 에서 시작하여 이터레이션(iteration)을 통하여 일련의 중간 단계의 해 \(\mathbf{x}^{(k)}\) 를 구하며 점진적으로 최적해에 접근하는 방법을 취한다.
이터레이션의 다음 단계의 해 \(\mathbf{x}^{(k+1)}\) 는 현 단계 해 \(\mathbf{x}^{(k)}\) 에서 일정 스텝(step) \(\Delta \mathbf{x}^{(k)}\) 으로 일정한 스텝사이즈 \(\eta^{(k)}\) 만큼 이동시켜 구하게 된다.
\[ \mathbf{x}^{(k+1)} = \mathbf{x}^{(k)} + \eta^{(k)} \Delta \mathbf{x}^{(k)} \tag{2} \]
\(\Delta \mathbf{x}^{(k)}\) 를 탐색 방향(search direction)이라고도 하는데, 경사하강법(gradient descent)에서는 목적함수 \(f(\mathbf{x})\) 의 그래디언트의 반대 방향인 \(\Delta \mathbf{x}^{(k)} = - \nabla f(\mathbf{x}^{(k)}) \) 를, 뉴턴방법(Newton's method)에서는 목적함수의 헤시안(Hessian)이 포함된 \( \Delta \mathbf{x}^{(k)}= - \left( \nabla^2 f(\mathbf{x}^{(k)}) \right)^{-1} \nabla f(\mathbf{x}^{(k)}) \) 를 사용한다.
스텝사이즈 \(\eta^{(k)}\) 는 크지고 작지도 않은 적당한 값으로 정해야 한다. 너무 크면 발산할 수 있고 너무 작으면 수렴 속도가 매우 느릴 수 있기 때문이다.
라인서치(line search)는 스텝사이즈 \(\eta\) 를 정하는 방법이다. 최적의 스텝사이즈는 다음과 같은 최적화 문제를 풀면 된다.
\[ \begin{align} & \min_{\eta} f(\mathbf{x}^{(k)} + \eta \Delta \mathbf{x}^{(k)} ) \tag{3} \\ \\ & \mbox{subject to : } \ \ \eta \ge 0 \end{align} \]
매 이터레이션 마다 또 다른 최적화 문제를 풀어야 하는 위 방법 대신에 실제로 많이 사용되는 방법은 백트래킹 라인서치(backtracking line search) 방법이다.
기본 개념은 스텝사이즈가 너무 작지 않도록 일단 탐색 방향으로 일정 사이즈만큼 이동한 후 점차 사이즈를 줄여가면서 목적함수의 값이 전 단계 이터레이션 값보다 작아지는지 확인하는 것이다.
0. \(\eta \gt 1\) (보통 \(\eta=1\)), \( \beta \in (0, 1)\) 을 설정한다.
1. 다음을 반복한다.
[1] \(f(\mathbf{x}^{(k)}+ \eta \Delta \mathbf{x}^{(k)}) \lt f(\mathbf{x}^{(k) })\) 이면 이터레이션을 중지한다.
[2] \(\eta \gets \beta \eta \)
위와 같은 백트래킹 라인서치 기본 알고리즘은 스텝사이즈가 너무 작아지는 것은 방지했지만, 너무 큰 크기의 스텝이 발생할 수 있는 단점이 있다. 이것을 보완하고자 다음과 같이 이터레이션 종료조건을 수정한 알고리즘이 많이 사용된다.
0. \(\eta \gt 1\) (보통 \(\eta=1\)), \( \beta \in (0, 1)\), \(\alpha \in (0, 0.5)\) 를 설정한다.
1. 다음을 반복한다.
[1] \(f(\mathbf{x}^{(k)}+ \eta \Delta \mathbf{x}^{(k)}) \lt f(\mathbf{x}^{(k) }) + \alpha \eta \nabla^T f(\mathbf{x}^{(k)}) \Delta \mathbf{x}^{(k)} \) 이면 이터레이션을 중지한다.
[2] \(\eta \gets \beta \eta \)
알고리즘 [1]의 이터레이션 종료조건에 의하면, \(f(\mathbf{x}^{(k)}+ \eta \Delta \mathbf{x}^{(k)})\) 의 값이 \(f(\mathbf{x}^{(k) }) \) 에서의 1차 테일러 근사화에 의해 계산되는 감소량 \(\eta \nabla^T f(\mathbf{x}^{(k)}) \Delta \mathbf{x}^{(k)}\) 의 일정 비율 \(\alpha\) 배 이상이라면 함수의 값이 충분히 감소했다고 간주한다.
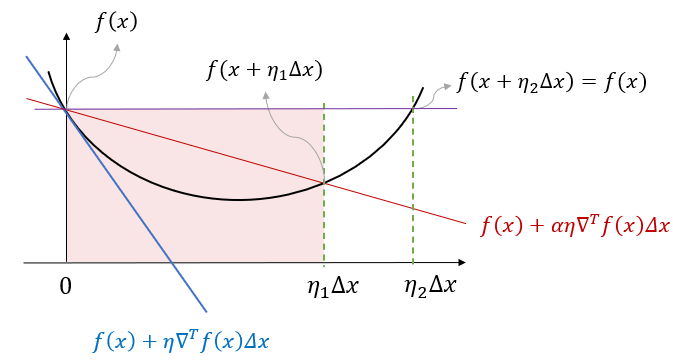
위 그림에서 보듯 기본 알고리즘에 의한 종료조건 (\(\eta_2 \Delta \mathbf{x}\)) 보다 수정 알고리즘의 종료조건 (\(\eta_1 \Delta \mathbf{x}\))이 스텝의 크기가 작다는 것을 알 수 있다.
'AI 수학 > 최적화' 카테고리의 다른 글
| 시뮬레이티드 어닐링 (Simulated Annealing) (0) | 2025.02.12 |
|---|---|
| 파티클 군집 최적화 (Particle Swarm Optimization) (0) | 2024.12.20 |
| 프라이멀-듀얼 내부점 방법 (Primal-Dual Interior-Point Method) (0) | 2022.04.15 |
| 장벽 내부점 방법 (Barrier Interior-Point Method) (0) | 2022.04.13 |
| 등식 제약조건에서의 뉴턴방법 (Newton’s Method) (0) | 2022.04.10 |




댓글