\(Y\)가 랜덤변수(random variable) \(X\)의 함수 \(Y=g(X)\)로 주어진다면 \(Y\)도 랜덤변수가 된다. \(X\)의 누적분포함수 \(F_X (x) \)와 확률밀도함수 \(p_X (x) \)로부터 \(F_Y (y) \)와 \(p_Y (y) \)를 구해보자.
사건 \( \{ Y \le y \} \)의 확률은 랜덤변수 \(X\)가 \( g(X) \le y \)를 만족하는 실수 구간 \( \{ X \in I_x \} \)에 속할 확률과 같으므로 \(Y\)의 누적분포함수는 다음 식으로 계산할 수 있다.
\[ \begin{align} F_Y (y) & = P \{ Y \le y \} \\ \\ &= P \{ g(X) \le y \} \\ \\ &= P \{ X \le g^{-1} (y) \} \\ \\ &= P \{ X \in I_x \} \end{align} \]
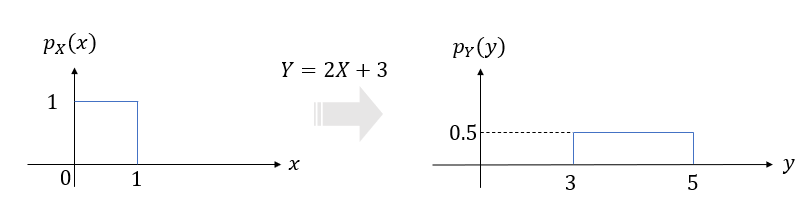
예를 들어서 다음과 같은 랜덤변수 \(X\)와 \(Y\)의 함수 관계가 있다고 가정하자.
\[ Y=2X+3 \]
그러면 \(Y\)의 누적분포함수는 다음과 같이 계산할 수 있다.
\[ \begin{align} F_Y (y) & = P \{ Y \le y \} \\ \\ &= P \{ 2X+3 \le y \} \\ \\ &= P \{ X \le \frac{1}{2}(y-3) \} \\ \\ &= F_X \left( \frac{y-3}{2} \right) \end{align} \]
만약 \(X\)가 \( [0,1] \) 구간에서 균등분포(uniform distribution)을 갖는다면, 즉 \( X \sim U[0,1] \)이라면
\[ p_X (x) = \begin{cases} 1, & 0 \le x \le 1 \\ 0, & others \end{cases} \]
\(Y\)의 확률밀도함수는 다음과 같이 계산할 수 있다.
\[ \begin{align} p_Y (y) & = \frac{dF_Y (y)}{dy} \\ \\ &= \frac{d}{dy} \left[ F_X \left( \frac{y-3}{2} \right) \right] \\ \\ &= \frac{1}{2} p_X \left( \frac{y-3}{2} \right) \\ \\ &= \begin{cases} \frac{1}{2}, & 3 \le y \le 5 \\ 0, & others \end{cases} \end{align} \]
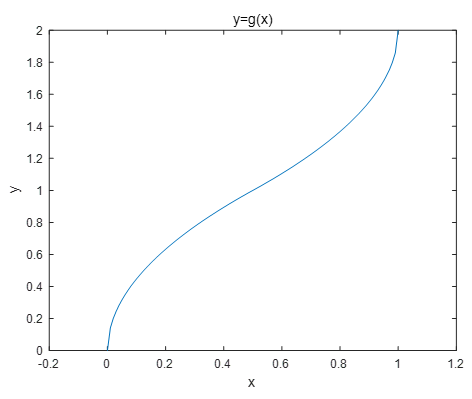
다른 예를 들어보자. 이번에는 다음과 같은 함수 관계가 있다고 가정하자.
\[ Y=g(X) = \begin{cases} \sqrt{2X}, & 0 \le X \lt \frac{1}{2} \\ 2-\sqrt{2(1-X)}, & \frac{1}{2} \le X \le 1 \\ 0, & others \end{cases} \]
그러면 \(Y\)의 누적분포함수는 다음과 같다.
\[ \begin{align} F_Y (y) & = P\{ Y \le y \} \\ \\ &= P \{ g(X) \le y \} \\ \\ &= P \{ X \le g^{-1} (y) \} \\ \\ &= P \begin{cases} X \le \frac{y^2}{2}, & 0 \le y \lt 1 \\ X \le 1- \frac{1}{2} (2-y)^2, & 1 \le y \le 2 \\ X \le 0, & others \end{cases} \\ \\ &= \begin{cases} F_X \left( \frac{y^2}{2} \right) , & 0 \le y \lt 1 \\ F_X \left( 1-\frac{1}{2} (2-y)^2 \right), & 1 \le y \le 2 \\ 0, & others \end{cases} \end{align} \]
따라서 \(Y\)의 확률밀도함수는 다음과 같이 계산할 수 있다.
\[ \begin{align} p_Y (y) & = \frac{dF_Y (y)}{dy} \\ \\ &= \begin{cases} \frac{d}{dy} \left[ F_X \left(\frac{y^2}{2} \right) \right], & 0 \le y \lt 1 \\ \frac{d}{dy} \left[ F_X \left( 1- \frac{1}{2} (2-y)^2 \right) \right], & 1 \le y \le 2 \\ 0, & others \end{cases} \\ \\ &= \begin{cases} y \ p_X \left( \frac{y^2}{2} \right) , & 0 \le y \lt 1 \\ (2-y) \ p_X \left( 1-\frac{1}{2} (2-y)^2 \right), & 1 \le y \le 2 \\ 0, & others \end{cases} \end{align} \]
만약 \(X\)가 \( [0,1] \) 구간에서 균등분포(uniform distribution)을 갖는다면,
\[ p_Y (y) = \begin{cases} y , & 0 \le y \lt 1 \\ (2-y), & 1 \le y \le 2 \\ 0, & others \end{cases} \]
이 된다.
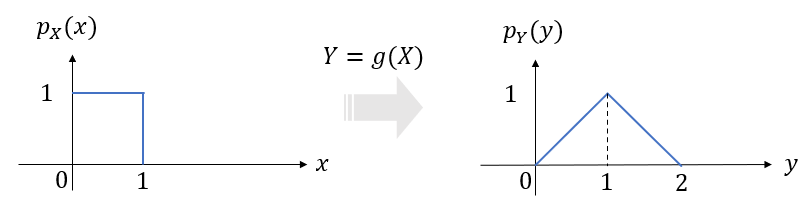
어떤 확률분포를 가진 랜덤변수에서 데이터를 생성하는 과정을 샘플링(sampling)이라고 한다. 파이썬(Python)이나 매트랩(Matlab)에는 가우시안 확률분포나 균등 확률분포를 갖는 랜덤변수에서 샘플을 추출할 수 있는 함수를 제공한다. 그렇다면 임의의 확률분포에서는 어떻게 샘플링 할 수 있을까.
랜덤변수 \(Y\)의 확률분포를 알고 있지만 샘플을 직접 추출하기 어려운 경우에는 균등 확률분포를 갖는 랜덤변수 \(X\)로부터 추출한 샘플 \( X=x^{(i)} \)을 함수 관계식 \(y^{(i)}=g(x^{(i)}) \)로 변환해서 \(Y\)로부터 추출한 샘플 \(Y=y^{(i)} \)로 간주하면 된다.
예를 들어서, 균등 확률분포를 갖는 \(X\)로부터 추출한 \(N\)개의 샘플 \(x^{(i)} \)로부터 다음과 같이 함수 \(y=g(x) \)를 통해 \(Y\)의 샘플 \(y^{(i)} \)를 구할 수 있다.
\[ y = g(x)= \begin{cases} \sqrt{2x} , & 0 \le x \lt \frac{1}{2} \\ 2-\sqrt{2(1-x)}, & \frac{1}{2} \le x \le 1 \\ 0, & others \end{cases} \]
다음 그림은 \(100,000 \)개의 샘플 \(x^{(i)} \)와 \(y^{(i)} \)를 이용해 근사적인 확률밀도함수를 그린 것(히스토그램)이다. 해석적으로 구한 확률밀도함수와 거의 일치함을 알 수 있다.

'AI 수학 > 랜덤프로세스' 카테고리의 다른 글
| 랜덤변수의 함수와 샘플링 - 3 (0) | 2020.12.26 |
|---|---|
| 랜덤변수의 함수와 샘플링 - 2 (0) | 2020.12.24 |
| 반복적인 기댓값 계산 (0) | 2020.12.12 |
| 베이즈(Bayes) 정리 (0) | 2020.11.13 |
| 샘플평균과 샘플분산 (0) | 2020.11.12 |




댓글