OpenAI Gym에서 제공하는 CartPole-v1 환경을 대상으로 DQN 알고리즘을 Tensorflow2 코드로 구현하였다.
폴이 카트에 조인트 되어 있고, 카트는 마찰 없는 트랙을 좌우로 이동할 수 있다. 폴은 처음에 수직으로 세워져 있으나 중력에 의해서 기울어져서 떨어질 수 있다. 카트의 목적은 폴이 떨어지지 않고 계속 수직으로 세워져 있도록 좌우로 이동하는 것이다. 상태변수는 카트의 위치와 속도, 폴의 각도와 속도 등 4개의 연속공간 값이고, 행동은 왼쪽 방향 이동과 오른쪽 방향이동 등 2개의 값만 있는 이산공간 값이다.
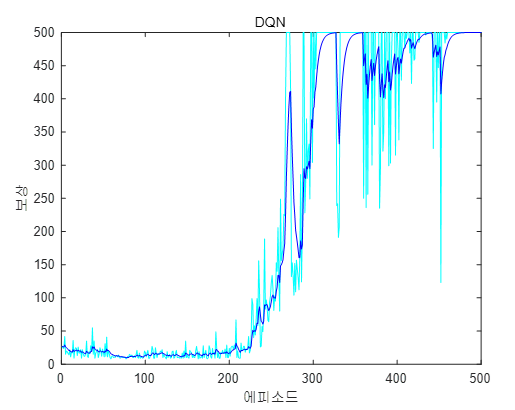
학습결과는 다음과 같다.
다음 영상은 학습 도중의 카트폴 움직임이다.
다음은 학습이 끝난 후 카트폴의 움직임이다.
DQN 코드는 Q 신경망을 구현하고 학습시키기 위한 dqn_learn.py, 이를 실행시키기 위한 dqn_main.py, 학습을 마친 신경망 파라미터를 읽어와 에이전트를 구동하기 위한 dqn_load_play.py 그리고 리플레이 버퍼를 구현한 replaybuffer.py로 구성되어 있다.
전체 코드 구조는 다음과 같다.

dqn_learn.py
# DQN learn (tf2 subclassing API version)
# coded by St.Watermelon
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
from replaybuffer import ReplayBuffer
# Q network
class DQN(Model):
def __init__(self, action_n):
super(DQN, self).__init__()
self.h1 = Dense(64, activation='relu')
self.h2 = Dense(32, activation='relu')
self.h3 = Dense(16, activation='relu')
self.q = Dense(action_n, activation='linear')
def call(self, x):
x = self.h1(x)
x = self.h2(x)
x = self.h3(x)
q = self.q(x)
return q
class DQNagent(object):
def __init__(self, env):
## hyperparameters
self.GAMMA = 0.95
self.BATCH_SIZE = 32
self.BUFFER_SIZE = 20000
self.DQN_LEARNING_RATE = 0.001
self.TAU = 0.001
self.EPSILON = 1.0
self.EPSILON_DECAY = 0.995
self.EPSILON_MIN = 0.01
self.env = env
# get state dimension and action number
self.state_dim = env.observation_space.shape[0] # 4
self.action_n = env.action_space.n # 2
## create Q networks
self.dqn = DQN(self.action_n)
self.target_dqn = DQN(self.action_n)
self.dqn.build(input_shape=(None, self.state_dim))
self.target_dqn.build(input_shape=(None, self.state_dim))
self.dqn.summary()
# optimizer
self.dqn_opt = Adam(self.DQN_LEARNING_RATE)
## initialize replay buffer
self.buffer = ReplayBuffer(self.BUFFER_SIZE)
# save the results
self.save_epi_reward = []
## get action
def choose_action(self, state):
if np.random.random() <= self.EPSILON:
return self.env.action_space.sample()
else:
qs = self.dqn(tf.convert_to_tensor([state], dtype=tf.float32))
return np.argmax(qs.numpy())
## transfer actor weights to target actor with a tau
def update_target_network(self, TAU):
phi = self.dqn.get_weights()
target_phi = self.target_dqn.get_weights()
for i in range(len(phi)):
target_phi[i] = TAU * phi[i] + (1 - TAU) * target_phi[i]
self.target_dqn.set_weights(target_phi)
## single gradient update on a single batch data
def dqn_learn(self, states, actions, td_targets):
with tf.GradientTape() as tape:
one_hot_actions = tf.one_hot(actions, self.action_n)
q = self.dqn(states, training=True)
q_values = tf.reduce_sum(one_hot_actions * q, axis=1, keepdims=True)
loss = tf.reduce_mean(tf.square(q_values-td_targets))
grads = tape.gradient(loss, self.dqn.trainable_variables)
self.dqn_opt.apply_gradients(zip(grads, self.dqn.trainable_variables))
## computing TD target: y_k = r_k + gamma* max Q(s_k+1, a)
def td_target(self, rewards, target_qs, dones):
max_q = np.max(target_qs, axis=1, keepdims=True)
y_k = np.zeros(max_q.shape)
for i in range(max_q.shape[0]): # number of batch
if dones[i]:
y_k[i] = rewards[i]
else:
y_k[i] = rewards[i] + self.GAMMA * max_q[i]
return y_k
## load actor weights
def load_weights(self, path):
self.dqn.load_weights(path + 'cartpole_dqn.h5')
## train the agent
def train(self, max_episode_num):
# initial transfer model weights to target model network
self.update_target_network(1.0)
for ep in range(int(max_episode_num)):
# reset episode
time, episode_reward, done = 0, 0, False
# reset the environment and observe the first state
state = self.env.reset()
while not done:
# visualize the environment
#self.env.render()
# pick an action
action = self.choose_action(state)
# observe reward, new_state
next_state, reward, done, _ = self.env.step(action)
train_reward = reward + time*0.01
# add transition to replay buffer
self.buffer.add_buffer(state, action, train_reward, next_state, done)
if self.buffer.buffer_count() > 1000: # start train after buffer has some amounts
# decaying EPSILON
if self.EPSILON > self.EPSILON_MIN:
self.EPSILON *= self.EPSILON_DECAY
# sample transitions from replay buffer
states, actions, rewards, next_states, dones = self.buffer.sample_batch(self.BATCH_SIZE)
# predict target Q-values
target_qs = self.target_dqn(tf.convert_to_tensor(
next_states, dtype=tf.float32))
# compute TD targets
y_i = self.td_target(rewards, target_qs.numpy(), dones)
# train critic using sampled batch
self.dqn_learn(tf.convert_to_tensor(states, dtype=tf.float32),
actions,
tf.convert_to_tensor(y_i, dtype=tf.float32))
# update target network
self.update_target_network(self.TAU)
# update current state
state = next_state
episode_reward += reward
time += 1
## display rewards every episode
print('Episode: ', ep+1, 'Time: ', time, 'Reward: ', episode_reward)
self.save_epi_reward.append(episode_reward)
## save weights every episode
self.dqn.save_weights("./save_weights/cartpole_dqn.h5")
np.savetxt('./save_weights/cartpole_epi_reward.txt', self.save_epi_reward)
## save them to file if done
def plot_result(self):
plt.plot(self.save_epi_reward)
plt.show()
dqn_main.py
# DQN main
# coded by St.Watermelon
from dqn_learn import DQNagent
import gym
def main():
max_episode_num = 500
env_name = 'CartPole-v1'
env = gym.make(env_name)
agent = DQNagent(env)
agent.train(max_episode_num)
agent.plot_result()
if __name__=="__main__":
main()
dqn_load_play.py
# DQN load and play
# coded by St.Watermelon
import gym
import numpy as np
import tensorflow as tf
from dqn_learn import DQNagent
def main():
env_name = 'CartPole-v1'
env = gym.make(env_name)
print(env.observation_space.shape[0]) # 4
# get action dimension
print(env.action_space, env.observation_space)
agent = DQNagent(env)
agent.load_weights('./save_weights/')
time = 0
state = env.reset()
while True:
env.render()
qs = agent.dqn(tf.convert_to_tensor([state], dtype=tf.float32))
action = np.argmax(qs.numpy())
state, reward, done, _ = env.step(action)
time += 1
print('Time: ', time, 'Reward: ', reward)
if done:
break
env.close()
if __name__=="__main__":
main()
replaybuffer.py
# Replay Buffer
# coded by St.Watermelon
import numpy as np
from collections import deque
import random
class ReplayBuffer(object):
"""
Reply Buffer
"""
def __init__(self, buffer_size):
self.buffer_size = buffer_size
self.buffer = deque()
self.count = 0
## save to buffer
def add_buffer(self, state, action, reward, next_state, done):
transition = (state, action, reward, next_state, done)
# check if buffer is full
if self.count < self.buffer_size:
self.buffer.append(transition)
self.count += 1
else:
self.buffer.popleft()
self.buffer.append(transition)
## sample a batch
def sample_batch(self, batch_size):
if self.count < batch_size:
batch = random.sample(self.buffer, self.count)
else:
batch = random.sample(self.buffer, batch_size)
# return a batch of transitions
states = np.asarray([i[0] for i in batch])
actions = np.asarray([i[1] for i in batch])
rewards = np.asarray([i[2] for i in batch])
next_states = np.asarray([i[3] for i in batch])
dones = np.asarray([i[4] for i in batch])
return states, actions, rewards, next_states, dones
## Current buffer occupation
def buffer_count(self):
return self.count
## Clear buffer
def clear_buffer(self):
self.buffer = deque()
self.count = 0
'AI 딥러닝 > RL' 카테고리의 다른 글
| Tensorflow2로 만든 Double DQN 코드: CartPole-v1 (0) | 2021.05.11 |
|---|---|
| Double DQN 알고리즘 (0) | 2021.05.11 |
| DQN 알고리즘 - 2 (0) | 2021.05.04 |
| DQN 알고리즘 - 1 (0) | 2021.05.02 |
| 가치 이터레이션에서 Q-러닝으로 (0) | 2021.05.01 |




댓글