 tf.reduce_sum 함수
tf.reduce_sum 은 텐서의 모든 성분의 총합을 계산하는 함수다. 예를 들어 다음과 같은 \(2 \times 1 \times 3\) 텐서 \(A\)를 구성하는 모든 성분의 총합을 구하기 위해서 tf.reduce_sum(A) 하면 21 이 나온다. 이 때 모든 차원(dimension)은 사라진다. import tensorflow as tf A = tf.constant([[[1, 2, 3]], [[4, 5, 6]]]) print("A=", A) print(tf.reduce_sum(A)) Output: A= tf.Tensor( [[[1 2 3]] [[4 5 6]]], shape=(2, 1, 3), dtype=int32) tf.Tensor(21, shape=(), dtype=int32) 텐서 \(A\)의..
2021. 3. 12.
tf.reduce_sum 함수
tf.reduce_sum 은 텐서의 모든 성분의 총합을 계산하는 함수다. 예를 들어 다음과 같은 \(2 \times 1 \times 3\) 텐서 \(A\)를 구성하는 모든 성분의 총합을 구하기 위해서 tf.reduce_sum(A) 하면 21 이 나온다. 이 때 모든 차원(dimension)은 사라진다. import tensorflow as tf A = tf.constant([[[1, 2, 3]], [[4, 5, 6]]]) print("A=", A) print(tf.reduce_sum(A)) Output: A= tf.Tensor( [[[1 2 3]] [[4 5 6]]], shape=(2, 1, 3), dtype=int32) tf.Tensor(21, shape=(), dtype=int32) 텐서 \(A\)의..
2021. 3. 12.
 넘파이(numpy)에서 행렬 모양 바꾸기, 자르기, 확장하기
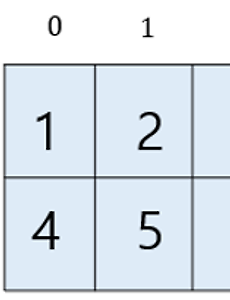
먼저 \(2 \times 3\) 행렬 \(A\)를 생성해 보자. \[ A = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} \] import numpy as np A = np.array([[1,2,3], [4,5,6]]) 이 행렬을 \(3 \times 2\) 로 바꾼 행렬 \(B\)를 만들려면 ndarray.reshape 라는 함수를 사용한다. \[ B = \begin{bmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix} \] B = A.reshape((3,2)) print("A=",A, "\nB=",B) 소괄호가 두 개가 있음에 주의해야 한다. 성분의 배치 순서는 행렬 \(A\)의 첫 행의 처음부터 시작하여 오른쪽으로 가면서..
2021. 3. 11.
넘파이(numpy)에서 행렬 모양 바꾸기, 자르기, 확장하기
먼저 \(2 \times 3\) 행렬 \(A\)를 생성해 보자. \[ A = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} \] import numpy as np A = np.array([[1,2,3], [4,5,6]]) 이 행렬을 \(3 \times 2\) 로 바꾼 행렬 \(B\)를 만들려면 ndarray.reshape 라는 함수를 사용한다. \[ B = \begin{bmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix} \] B = A.reshape((3,2)) print("A=",A, "\nB=",B) 소괄호가 두 개가 있음에 주의해야 한다. 성분의 배치 순서는 행렬 \(A\)의 첫 행의 처음부터 시작하여 오른쪽으로 가면서..
2021. 3. 11.













